library(tidyverse)
library(easystats)6 Punktmodelle 1
Schlüsselwörter
Statistik, Prognose, Modellierung, R, Datenanalyse, Regression
\[ \definecolor{ycol}{RGB}{230,159,0} \definecolor{modelcol}{RGB}{86,180,233} \definecolor{errorcol}{RGB}{0,158,115} \definecolor{beta0col}{RGB}{213,94,0} \definecolor{beta1col}{RGB}{0,114,178} \definecolor{xcol}{RGB}{204,121,167} \]
6.1 Einstieg
In diesem Kapitel benötigen Sie die üblichen R-Pakete (tidyverse, easystats) und Daten (mariokart), s. Kapitel 3.7.3 und Kapitel 3.4.
mariokart <- read.csv("https://vincentarelbundock.github.io/Rdatasets/csv/openintro/mariokart.csv")6.1.1 Lernziele
- Sie können gängige Arten von Lagemaße definieren.
- Sie können erläutern, inwiefern man ein Lagemaß als ein Modell verstehen kann.
- Sie können Lagemaße mit R berechnen.
6.2 Mittelwert als Modell
Der “klassische” Mittelwert (das arithmetische Mittel) ist ein prototypisches Beispiel für ein Modell in der Statistik.
Übungsaufgabe 6.1 Welche Vorstellung haben Sie, wenn Sie hören, dass der “typische deutsche Mann” 1.80 m groß ist (vgl. Roser et al., 2013)?
- Die Hälfte der Männer ist größer als 1.80\(\,\)m, die andere Hälfte kleiner.
- Das arithmetische Mittel der Männer beträgt 1.80\(\,\)m.
- Die meisten Männer sind 1.80\(\,\)m groß.
- Etwas anderes.
- Keine Ahnung! \(\square\)
Übungsaufgabe 6.2 Laut dem Statistischen Bundesamt (2023-003-27) beträgt der Wert der mittleren Größe deutscher Frauen etwa 1.66\(\,\)m, also 14\(\,\)cm weniger als bei Männern.1 \(\square\)
Ist das viel?
- ja
- nein
- kommt drauf an
- weiß nicht \(\square\)
Auf diese Frage gibt es keine Antwort, zumindest nicht ohne weitere Annahmen. So könnte man z.\(\,\)B. sagen, “mehr als 5 cm sind viel”. So eine Entscheidung ist aber keine statistische Angelegenheit, sondern eine inhaltliche.
Beispiel 6.1 (Beispiel zum Mittelwert) Ein Statistikkurs besteht aus drei Studentinnen: Anna, Berta und Carla. Sie haben gerade ihre Noten in der Klausur erfahren. Anna hat eine 1, Berta eine 2 und Carla eine 3. Der Durchschnitt (das arithmetische Mittel, \(\varnothing\)) beträgt: 2. \(\square\)
🧑🎓 Zu easy!
🧑🏫 Schon gut! Chill mal. Wird gleich spannender.
Die Rechenregel zum Mittelwert lautet:
- Addiere alle Werte
- Teile durch die Anzahl der Werte
- Fertig!
Etwas abstrakter kann man Beispiel 6.1 in folgendem Schaubild darstellen, s. Abbildung 6.1.
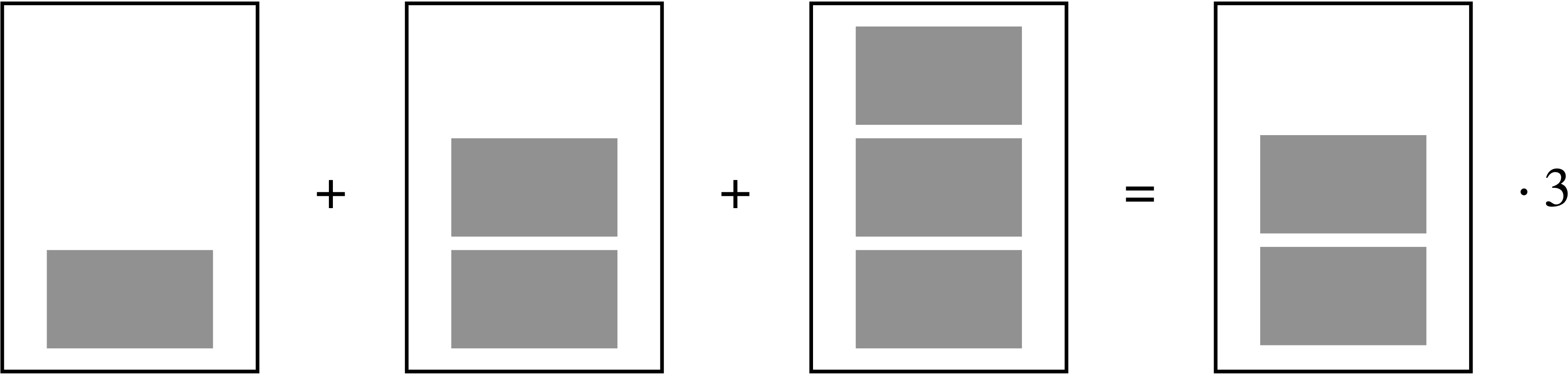
Das Beispiel zeigt uns: Der Mittelwert eines Vektors \(X\) ist die Zahl, die \(n\) mal multipliziert, gleich ist mit der Summe der \(n\) Elemente von \(X\). Der Nutzen des Mittelwerts liegt darin, dass er uns ein Bild gibt (ein Modell ist!) für die “typische Note” im Statistikkurs, s. Abbildung 6.5.
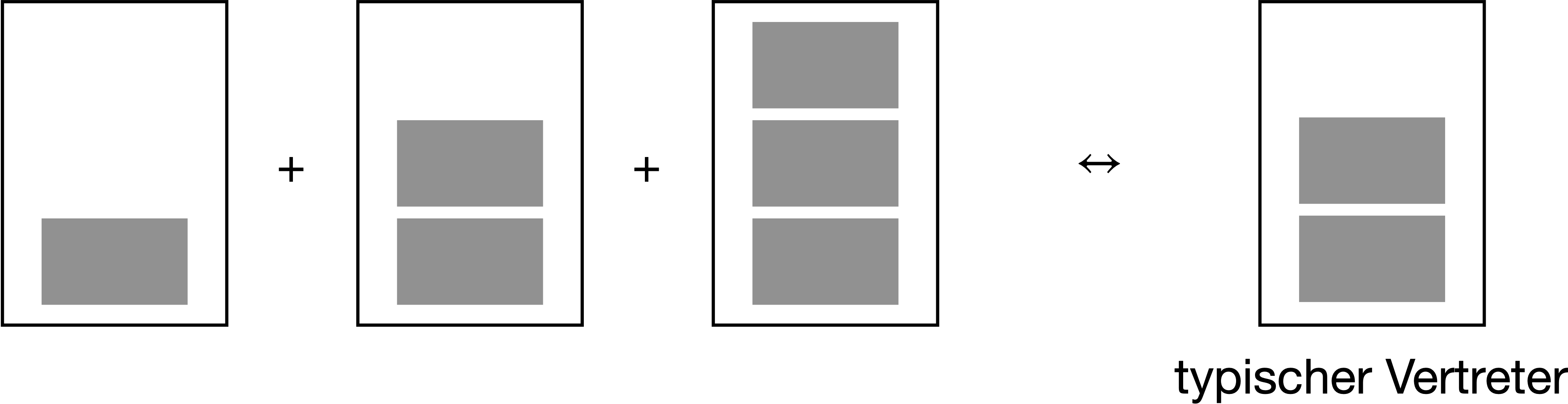
Der Nutzen des Mittelwerts liegt darin, dass er einen Vektor (eine “Datenreihe”) zu einen “typischen Vertreter” zusammenfasst. Er ist typisch in dem Sinne, als dass die Werte aller Merkmalsträger in gleichem Maße einfließen. Er gibt uns eine (mögliche) Vorstellung (ein Modell!), wie wir uns die Werte der Datenreihe vorstellen sollen. Eine nützliche Anschauung zum Mittelwert ist die Vorstellung des Mittelwerts als eine ausbalancierte Wippe, s. Abbildung 6.3. In “Mathe-Sprech” bezeichnet man den Mittelwert häufig mit \(\bar{x}\) und schreibt die Rechenregel so, s. Gleichung 6.1.

\[\bar {x} :=\frac{1}{n} \sum_{i=1}^{n}{x_{i}}=\frac {x_{1}+x_{2}+\dotsb +x_{n}} {n} \tag{6.1}\]
Definition 6.1 (Mittelwert) Der Mittelwert (MW, mean) von \(X\) (präziser: das arithmetische Mittel des Merkmals \(X\)) ist definiert als die Summe der Elemente von \(X\) geteilt durch deren Anzahl, \(n\). Den Mittelwert von \(X\) bezeichnet man auch mit \(\bar {x}\). \(\square\)
Beispiel 6.2 Angenommen, wir haben eine Reihe von Noten: 1, 2, 3. Der Mittelwert der Noten beträgt dann 2: \(\bar{X} = \frac{1}{3}\sum (1+2+3) = 6/3 = 2\). \(\square\)
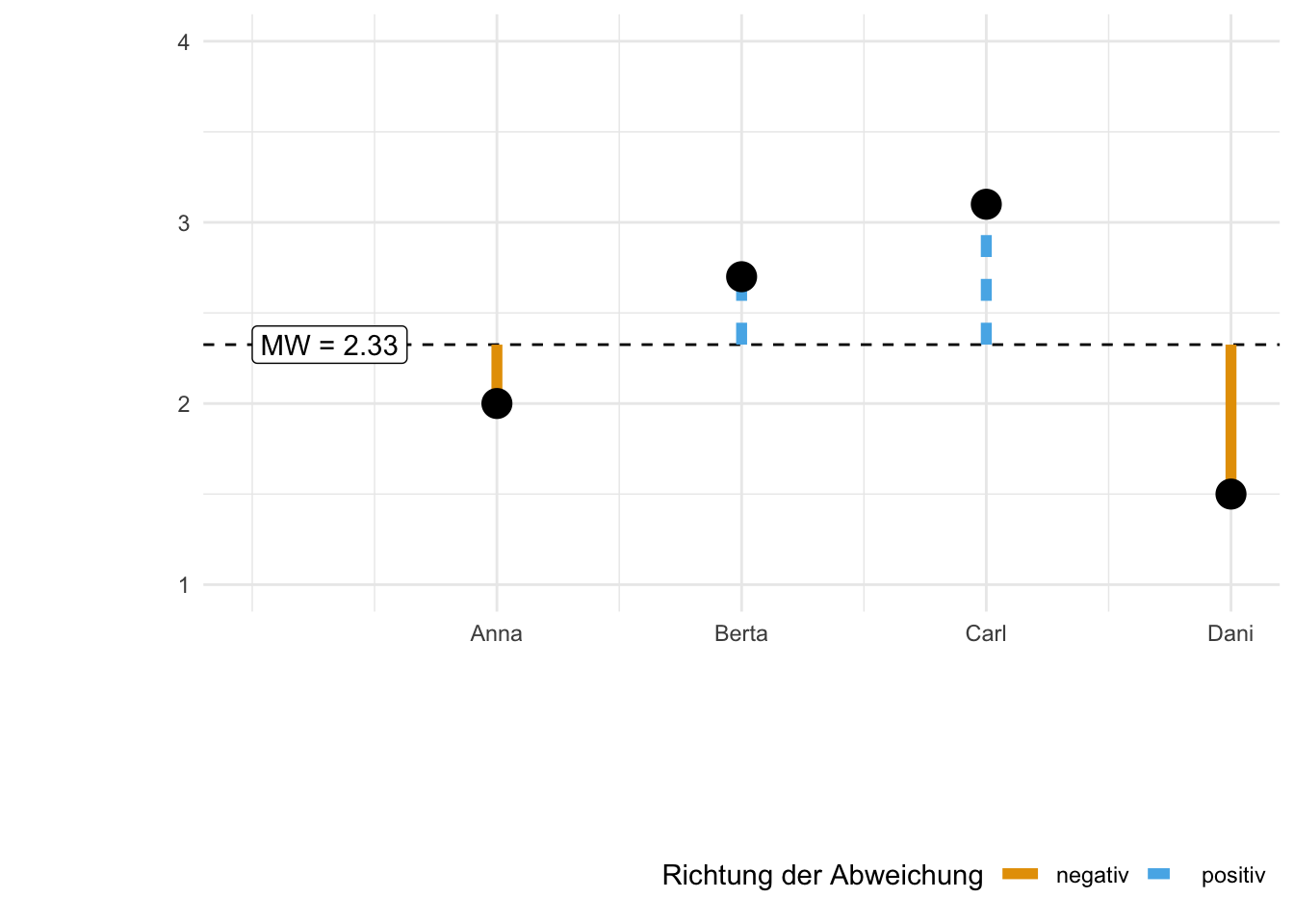
Da der Mittelwert eine zentrale Rolle spielt in der Statistik, sollten wir ihn uns noch etwas genauer anschauen. In s. Abbildung 6.4 sehen wir die Noten von (dieses Mal) vier Studentinnen. Die gestrichelte horizontale Linie zeigt den Mittelwert der vier Noten. Die schwarzen Punkte sind die Daten, in dem Fall die einzelnen Noten. Die vertikalen Linien zeigen die Abweichungen der Noten zum Mittelwert.
Bezeichnen wir die Abweichung – auch als “Fehler”, “Rest” oder “Residuum” bezeichnet – der \(i\)-ten Person mit \(\color{errorcol}{\text{e}_i}\) (e wie engl. error, Fehler) und die \(i\)-te Note mit \(\color{ycol}{y_i}\), so können wir mit Gleichung 6.2 festhalten:
\[\color{ycol}{\text{y}_i} \color{black}{ = } \color{modelcol}{\;\bar{x}\;} + \color{errorcol}{\;\text{e}_i} \tag{6.2}\]
Anders ausgedrückt (s. Gleichung 6.3):
\[\color{ycol}{\text{Daten}} \color{black}{ = } \color{modelcol}{\text{Modell}} + \color{errorcol}{\text{Rest}} \tag{6.3}\]
Der Mittelwert ist hier unser Modell der Daten. Wie gesagt: Ein Modell ist eine vereinfachte (zusammengefasste) Beschreibung einer Datenreihe. Um Modelle darzustellen, wird in der Datenanalyse häufig folgende Art von Modellgleichung verwendet, s. Gleichung 6.4.
\[\color{modelcol}{\hat{y}} \sim \color{xcol}{\text{ x}} \tag{6.4}\]
Lies: “Der Modellwert \(\color{modelcol}{\hat{y}}\) ist eine Funktion der Variable \(\color{xcol}{\text{x}}\)”. Der Kringel “~” soll also hier heißen “ist eine Funktion von”. Das “Kringel” oder die “Welle” ~ nennt man auch “Tilde”.
Mit \(\color{modelcol}{\hat{y}}\) ist die vorhergesagte bzw. die zu erklärende Variable (synonym: AV, Output-Variable, Zielvariable) gemeint. Das “Dach” über dem \(\color{ycol}{\text{y}}\) bedeutet “vorhergesagter Y-Wert” oder “Y-Wert laut dem Modell”. Der tatsächliche, beobachtete Wert \(\color{ycol}{\text{y}}\) setzt sich zusammen aus dem Modellwert \(\color{modelcol}{\text{m}}\) plus einem Fehler \(\color{errorcol}{\text{e}}\), s. Gleichung 6.5.
\[\color{ycol}{y} \color{black}{\, = \,} \color{modelcol}{\text{m}} + \color{errorcol}{\text{e}} \tag{6.5}\]
Anstelle von \(\color{modelcol}{\text{m}}\) schreibt man auch \(\color{modelcol}{\hat{y}}\) (“y-Dach”). In diesem Fall ist das Modell einfach gleich dem Mittelwert (und nicht irgendeiner Funktion des Mittelwerts), so dass wir mit Gleichung 6.6 schreiben können:
\[\color{ycol}{y} \color{black}{\, =\, } \color{modelcol}{\bar{x}} + \color{errorcol}{e} \tag{6.6}\]
Die Zielvariable \(\color{ycol}{\text{y}}\) wird also durch ihren eigenen Mittelwert erklärt, außer gehen wir von einem Fehler \(\color{errorcol}e\) in unseren Modellvorhersagen aus. Nobody is perfect. In späteren Kapiteln werden wir andere Variablen heranziehen, um die Zielvariable zu erklären. Würden wir z.\(\,\)B. sagen wollen, dass wir \(\color{ycol}{\text{y}}\) als Funktion einer Variable \(\color{xcol}{X}\) erklären, so würden wir schreiben (s. Gleichung 6.7):
\[\color{modelcol}{\bar{y}} \color{black} {\, \sim \,} \color{xcol}{\text{ x}} \tag{6.7}\]
Da wir im Moment aber keine andere Variablen bemühen, um \(\color{ycol}{\text{y}}\) zu erklären, schreibt man mit Gleichung 6.8 auch:
\[\color{modelcol}{\bar{y}}\;\; \color{black}{\sim \; 1} \tag{6.8}\]
Diese Schreibweise sieht anfangs verwirrend aus. Die \(1\) soll aber nur zeigen, dass wir keine andere Variable zur Erklärung von \(\color{ycol}{\text{y}}\) verwenden, daher steht hier kein Buchstabe, sondern eine einfache \(1\). Der mathematische Hintergrund liegt in der Art, wie man Matrizen multipliziert.
Beispiel 6.3 (Noten, Mittelwert und Abweichung) Vier Studentinnen – Anna, Berta, Carl, Dani – haben ihre Statistik-Klausur zurückbekommen (Schluck). Die Noten sehen Sie in Abbildung 6.4; gar nicht so schlecht ausgefallen. Außerdem ist der Mittelwert (gestrichelte horizontale Linie) sowie die Abweichungen Residuen, Fehler; häufig mit \(e\) wie error bezeichnet) der einzelnen Noten vom Mittelwert eingezeichnet. \(\square\)
Schauen Sie sich die Abweichungsbalken in Abbildung 6.4 einmal genauer an. Jetzt stellen Sie sich vor, Sie würden die vom Mittelwert nach oben ragenden Balkenlängen aneinanderlegen (das sind die gestrichelten. Können Sie sich das vorstellen? Jetzt legen Sie auch noch die Abweichungsbalken, die nach unten ragen, aneinander (die mit den durchgezogenen Linien). Wer viel Phantasie hat, erkennt (sieht), dass die Gesamtlänge der “nach oben ragenden Balken” identisch ist zur Gesamtlänge der nach “unten ragenden Balken”. Gleichung 6.9 drückt das präziser und ohne Ihre Phantasie zu strapazieren aus.
Wie man in Gleichung 6.9 sieht, ist die Summe der Abweichungen vom Mittelwert Null.
Übungsaufgabe 6.3 Was schätzen Sie, wie hoch das mittlere Vermögen (arithmetisches Mittel) der Haushalte in Deutschland in etwa ist (im Jahr 2021 auf Basis einer Umfrage) (Bundesbank, 2023)?2 \(\square\)
- 50.000 Euro
- 100.000 Euro
- 150.000 Euro
- 200.000 Euro
- 300.000 Euro
Beispiel 6.4 (Der wertvollste Fußballer der Welt in Ihrem Hörsaal) Kommt der wertvollste Fußballspieler der Welt in Ihren Hörsaal, sagen wir, es ist Kylian Mbappé (Transfermarkt, 2024). Sein Jahreseinkommen (2023) liegt bei ca. 120 Millionen Euro (Arad, 2024). Der Fußballer ist gut gelaunt:
🦹 Hey Leute, wie geht’s denn so! Wie viel Kohle habt ihr eigentlich so?
🧑🎓 Äh, wir studieren und verdienen fast nix!
Die 100 Studis im Hörsaal schauen verdattert aus der Wäsche: Was ist das für eine komische Frage!? Aber zumindest verteilt der Fußballspieler Autogramme.
Übungsaufgabe 6.4 (Mittleres Einkommen im Hörsaal, mit Kylian Mbappé) Schätzen Sie – im Kopf – das mittlere Vermögen im Hörsaal, gehen Sie davon aus, dass alle der 100 Studierenden jeweils 1000 Euro im Jahr verdienen. \(\square\)
In R kann man das mittlere Einkommen (präziser: das arithmetische Mittel des Einkommens) wie folgt berechnen, s. Listing 6.1. (Die Details der Syntax, z.\(\,\)B. der Befehl rep, sind von geringer Bedeutung.)
set.seed(42) # Zufallszahlen festlegen, hier nicht so wichtig
einkommen_studis <- rep(x = 1000, times = 100) # "rep" wie "repeat": wiederhole 1000 USD 100-mal
einkommen <- c(einkommen_studis, 120*1e6) # 100 Studis mit 1000, 1 Mbappé mit 120 Mio
einkommen_mw <- mean(einkommen)
einkommen_mw
## [1] 1189109
Hinweis
1 Million hat 6 Nullen hinter der führenden Eins: 1000000. In Taschenrechner- oder Computerschreibweise: 1 Mio = 1e6, das 1e6 ist zu lesen als “1 Mal 10 hoch 6, also mit 6 im Exponenten”.
Der Mittelwert im Hörsaal beträgt also 1,189,109 Euro, etwas mehr als eine Million. Ist das ein gutes Modell für das typische Vermögen im Hörsaal?3
6.2.1 Der Mittelwert als lineares Modell
Man kann den Mittelwert als Gerade einzeichnen, s. Abbildung 6.5, bzw. als Gerade begreifen. Insofern kann man vom Mittelwert auch als lineares Modell sprechen.
Definition 6.2 (Lineares Modell) Ein lineares Modell beschreibt die Daten durch eine Gerade. Es erklärt die Daten anhand einer Geraden. \(\square\)
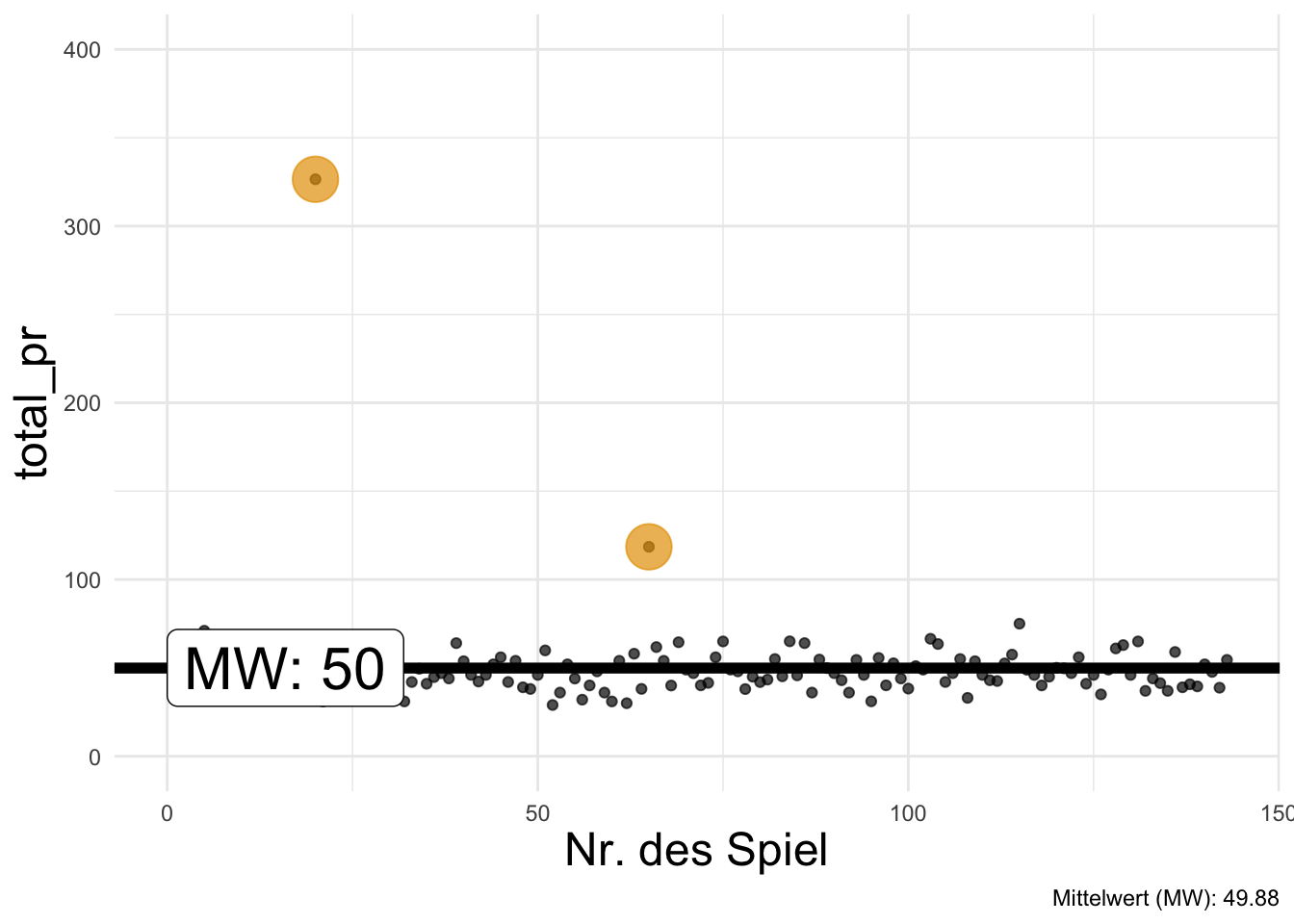
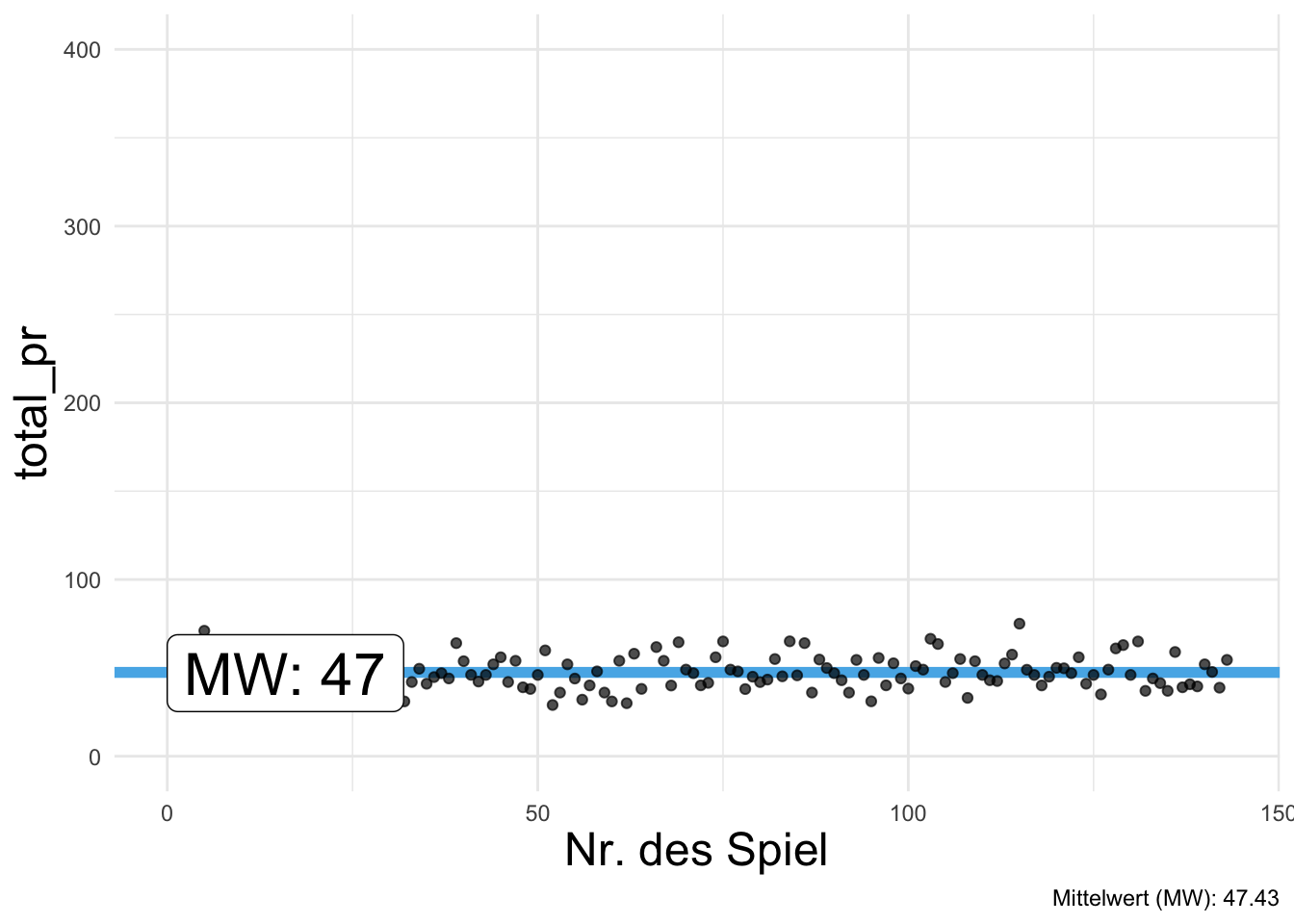
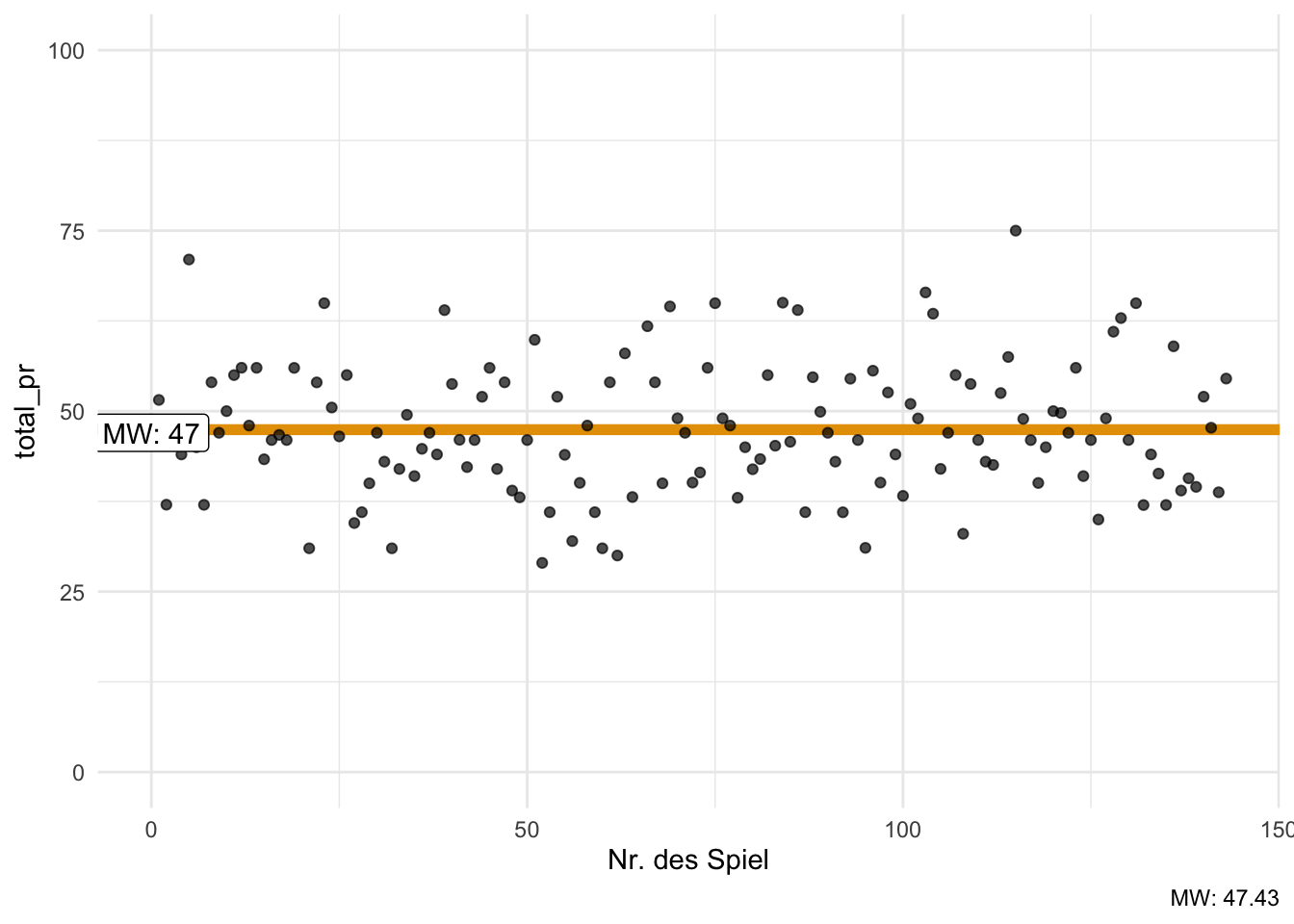
Abbildung 6.5 zeigt den Mittelwert des Verkaufspreises der Mariokart-Spiele (total_pr), einmal mit (farbig markierten) Extremwerten (a) bzw. einmal ohne Extremwerte (b).
Definition 6.3 (Extremwert) Ein Extremwert (Ausreißer; outlier) ist eine Beobachtung, deren Wert deutlich vom Großteil der anderen Beobachtungen im Datensatz abweicht, z.\(\,\)B. viel größer ist. \(\square\)
Berechnen wir mal den Mittelwert von einkommen mit R mit dem Befehl lm.
lm(einkommen ~ 1) # lm wie "lineares Modell" oder engl. "linear model"
##
## Call:
## lm(formula = einkommen ~ 1)
##
## Coefficients:
## (Intercept)
## 1189109Der Befehl lm gibt hier mit der Ausgabe Coeffients (Koeffizient) einen einzelnen Wert zurück und zwar den Mittelwert von einkommen, vgl. auch Listing 6.1. Dieser Wert wird als Achsenabschnitt (engl. intercept) bezeichnet. Das wird verständlich, wenn man z.\(\,\)B. in Abbildung 6.5 sieht, dass die Gerade (des Mittelwerts) genau an diesem Punkt die Y-Achse schneidet. Die Syntax des Befehls lm() sieht etwas merkwürdig aus. Ignorieren Sie das fürs Erste, wir besprechen das später (Kapitel 9) ausführlich. lm steht übrigens für “lineares Modell”.
6.3 Der Median als Modell
🧑🎓 Hey, der Mittelwert ist doch Quatsch! Das ist gar kein typischer Wert für die Menschen im Hörsaal. Weder für Mbappé, noch für uns Studis!
🧑🏫 Ja, da habt ihr Recht.
⚽ Die Welt ist schon ungerecht!
Abbildung 6.6 stellt die Verteilung des Einkommens im Hörsaal dar. Zur Erinnerung: 4.0+e07 bedeutet \(4 \cdot 10^{07} = 40000000\), eine 4 gefolgt von 7 Nullen.

Der Mittelwert ist Hörsaal ist nicht typisch für die Menschen im Hörsaal: Weder für Mbappé, noch für die Studis. Genau genommen ist der Mittelwert in diesem Fall ziemlich nutzlos. Der Mittelwert ist anfällig für Extremwerte: Gibt es einen Extremwert in einer Datenreihe, so spiegelt der Mittelwert stark diesen Wert wider und weniger die Mehrheit der gemäßigten Werte. Man sagt, der Mittelwert ist nicht robust (gegenüber Extremwerten).
Wichtig
Bei (sehr) schiefen Verteilungen (s. Abbildung 6.6) ist der Mittelwert (sehr) wenig aussagekräftig, da er nicht mehr “typische” Werte für die Merkmalsträger beschreibt.
Beispiel 6.5 (Das Median-Einkommen einiger Studentinnen) Fünf Studentinnen tauschen sich über ihr Einkommen aus, s. Abbildung 6.7, links. Es handelt sich um eine schiefe Verteilung. Wir könnten jetzt behaupten, dass Carla das typische Einkommen (für diese Datenreihe) aufweist, da es genauso viele Studentinnen gibt, die mehr verdienen, wie solche, die weniger verdienen. \(\square\)
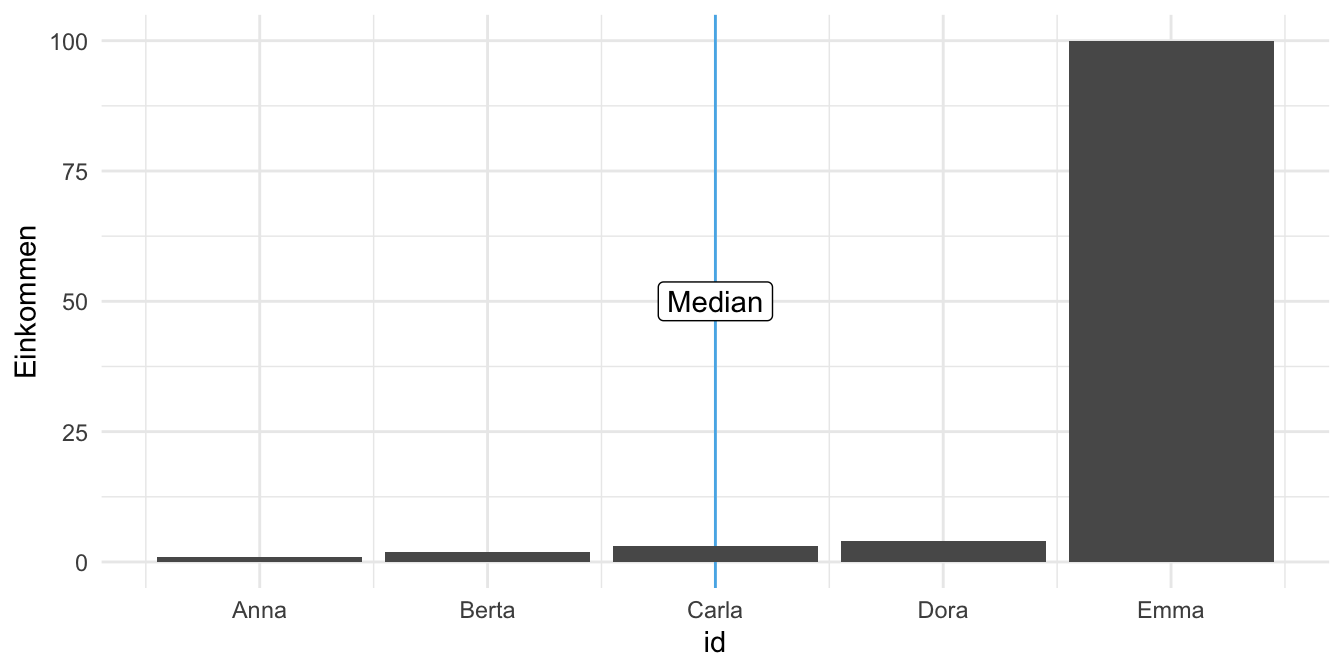
Definition 6.4 (Median) Die Merkmalsausprägung, die bei (aufsteigend) sortierten Beobachtungen in der Mitte liegt, nennt man Median. \(\square\)
Übungsaufgabe 6.5 (Alle mal aufstehen) Auf Geheiß der Lehrkraft stehen jetzt alle Studis bitte auf und sortieren sich der Größe nach im Raum, schön in einer Reihe aufgestellt. Die Körpergröße der Person in der Mitte der Reihe, zu der also gleich viele Personen zu links wie zu rechts stehen, das ist der Medien dieser Datenreihe, vgl. Abbildung 6.8. \(\square\)
Der Median ist robust gegenüber Extremwerten: Fügt man Extremwerte zu einer Verteilung hinzu, ändert sich der Median zumeist (deutlich) weniger als der Mittelwert. Abbildung 6.8 stellt den Median schematisch dar.

Bei geradem \(n\) werden die beiden mittleren Werte betrachtet und das arithmetische Mittel aus diesen beiden Werten gebildet.
Beispiel 6.6 Bei der Messreihe 1,2,3 beträgt der Median 2. Bei der Messreihe 1, 2 beträgt der Median 1.5. \(\square\)
Übungsaufgabe 6.6 (Emma wird reich) Durch ein geniales Patent wird Emma steinreich. Ihr Einkommen erhöht sich um das Hundertfache. Wie verändert sich der Median?4 \(\square\)
Übungsaufgabe 6.7 (Wer ist mehr “mittel”? Median oder Mittelwert?)
🧑🎓 Das arithmetische Mittel sollte Mittelwert heißen, weil es die Mitte des Abstands zweier Zahlen widerspiegelt, also z.\(\,\)B. von 1 und 10 ist die Mitte 5.5 – also genau beim Mittelwert!
👩 Moment! Der Median und nur der Median zeigt den mittleren Messwert! Links und rechts sind gleich viele Messwerte, wenn man die Werte der Größe nach sortiert. Also liegt der Median genau in der Mitte!
Nehmen Sie Stellung zu dieser Diskussion! \(\square\)
Beispiel 6.7 (Ein “mittlerer” Preis für Mariokart) Der Mittelwert (das arithmetische Mittel) und der Median für das Start-Gebot (start_pr) von Mariokart-Spielen sind nicht gleich, der Mittelwert ist höher als der Median.
mariokart %>%
summarise(price_mw = mean(start_pr),
price_md = median(start_pr))| price_mw | price_md |
|---|---|
| 8.8 | 1 |
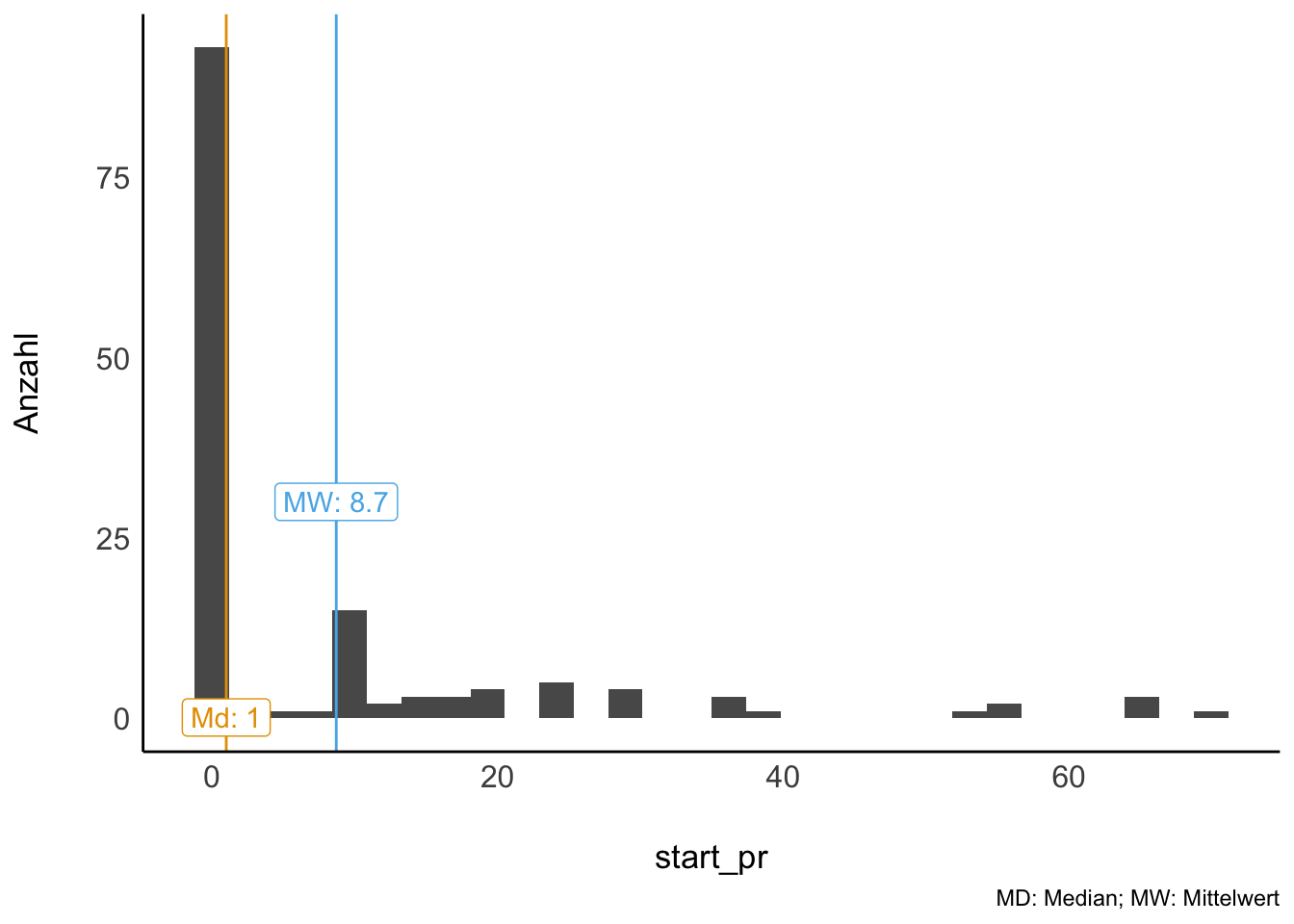
Wie man sieht, ist der Mittelwert größer als der Median, s. Abbildung 6.9. \(\square\)
Klaffen Mittelwert und Median auseinander, so liegt eine schiefe Verteilung vor. Ist der Mittelwert größer als der Median, so nennt man die Verteilung rechtsschief. Bei schiefen Verteilungen ist der Median dem Mittelwert als Modell für den “typischen Wert” vorzuziehen.
Übungsaufgabe 6.8 (Mariokart ohne Extremwerte) Im Datensatz mariokart gibt es einige wenige Spiele, die für einen vergleichsweise hohen Preis verkauft wurden. Diese Extremwerte verzerren den mittleren Verkaufspreis möglicherweise über die Gebühr.
Entfernen Sie diese Werte und berechnen Sie dann Mittelwert und Median erneut. Vergleichen Sie die Ergebnisse.
Lösung
mariokart_no_extreme <-
mariokart %>%
filter(total_pr < 100)
# mit Extremwerten:
mariokart |>
summarise(total_pr_mittelwert = mean(total_pr),
total_pr_median = median(total_pr))
# ohne Extremwerte:
mariokart_no_extreme |>
summarise(total_pr_mittelwert_no_extreme = mean(total_pr),
total_pr_median_no_extreme = median(total_pr))| total_pr_mittelwert | total_pr_median |
|---|---|
| 50 | 46 |
| total_pr_mittelwert_no_extreme | total_pr_median_no_extreme |
|---|---|
| 47 | 46 |
Wie man sieht, verändert sich der Mittelwert, wenn man die Extremwerte entfernt. Für den Median trifft das nicht zu, er bleibt, wo er ist. \(\square\)
Übungsaufgabe 6.9 (Das mediane Vermögen in Deutschland) Was schätzen Sie, wie hoch das mediane Vermögen der Haushalte in Deutschland im Jahr 2021 in etwa war (Bundesbank, 2023)?5
- 50 Tsd Euro
- 100 Tsd Euro
- 150 Tsd Euro
- 200 Tsd Euro
- 300 Tsd Euro\(\square\)
6.4 Quantile
6.4.1 Quantile als Verallgemeinerung des Medians
Der Median teilt eine Verteilung in eine untere und ein obere Hälfte. Er markiert sozusagen eine “50-Prozent-Marke” (der aufsteigend sortierten Werte). Betrachten wir einmal nur alle Spiele, die für weniger als 100 Euro verkauft wurden (total_pr, finales Verkaufsgebot), s. Abbildung 6.10. 50\(\,\)% dieser Spiele wurden für weniger als ca. 46 Euro verkauft und 50% für mehr als 46 Euro. Der Median beträgt als 46 Euro.
Jetzt könnten wir nur die günstigere Hälfte betrachten und wieder nach dem Median fragen (d.\(\,\)h. total_pr < 46). Dieser “Median der billigeren Hälfte” grenzt damit das insgesamt billigste Viertel vom Rest der Verkaufsgebote ab. In unserem Datensatz liegt dieser Wert bei ca. 41 Euro. Entsprechend kann man nach dem Wert fragen, der das oberste Viertel vom Rest der Verkaufsgebote abtrennt. Dieser Wert liegt bei ca. 54 Euro. Jetzt könnte man sagen, hey, warum nur in 25\(\,\)%-Stücke die Verteilung aufteilen? Warum nicht in 10\(\,\)%-Schritten? Oder vielleicht in 1\(\,\)%-Schritten oder in sonstigen Schritten? Wo die Quartile in 25\(\,\)%-Schritten aufteilen, teilt ein Quantil in \(p\)-Prozent-Schritten auf. S. Abbildung 6.11 dazu.
6.4.2 Quartile, Dezile und Perzentile
Definition 6.5 (Quartile) Sortiert man die Daten aufsteigend, so nennt man den Wert, der das Viertel mit den kleisten Wert vom Rest der Daten trennt das erste Quartil (Q1, 25\(\,\)%). Den Median nennt man das zweite Quartil (Q2, 50\(\,\)%). Entsprechend heißt der Wert, der die drei Viertel kleinsten Werte vom oberen Viertel abtrennt, das dritte Quartil (Q3, 75\(\,\)%). \(\square\)
Beispiel 6.8 (Quartile des Verkaufsgebot) Abbildung 6.10 zeigt die Quartile für das Verkaufsgebot. \(\square\)
Definition 6.6 (Dezile) Die neun Quantile \(p= 0.1, 0.2, \ldots, 1\), die die Verteilung in 10 gleich große Teile unterteilen, nennt man Dezile. “Gleich groß” heißt, dass in jedem Dezil gleich viele Werte (nämlich 10 %) liegen. \(\square\)
Abbildung 6.10 zeigt das 1. (Q1), das 2. (Median) und das 3. Quartil für den Datensatz mariokart2.
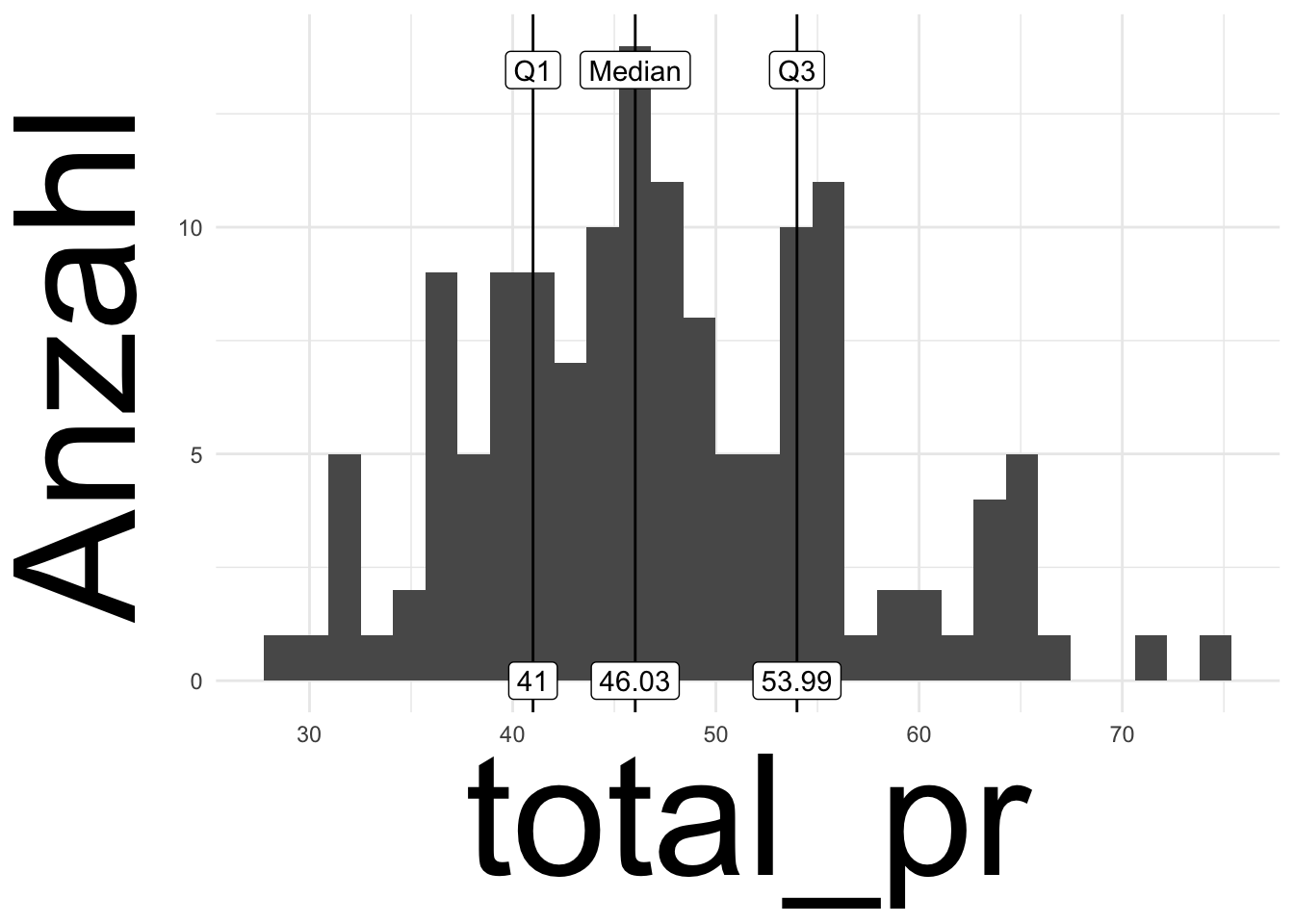
Definition 6.7 (Quantile) Ein \(p\)-Quantil ist der Wert, der von \(p\) Prozent der Werte nicht überschritten wird. Ein Quantil ist ein Oberbegriff für Quartile, Dezile etc. \(\square\)
Quantile kann man in R mit dem Befehl quantile berechnen:
mariokart %>%
filter(total_pr < 100) %>%
summarise(
q25 = quantile(total_pr, .25), # 1. Quartil
q50 = quantile(total_pr, .50), # 2. Quartil
q75 = quantile(total_pr, .75)) # 3. QuartilAbbildung 6.11 stellt einige Quantile animiert dar.
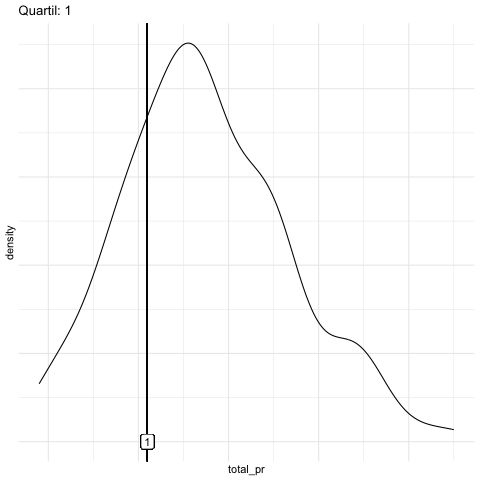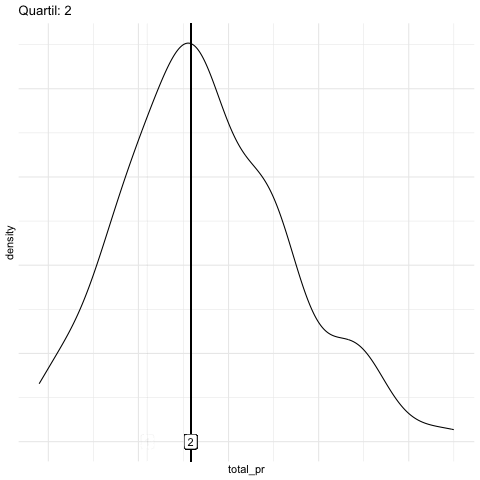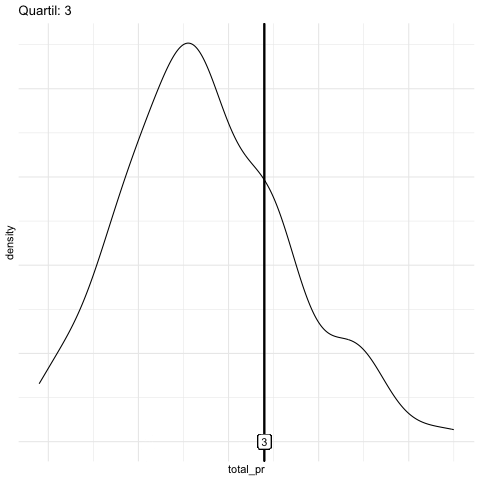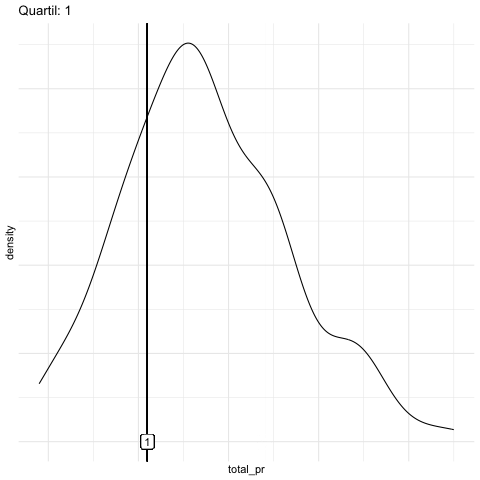


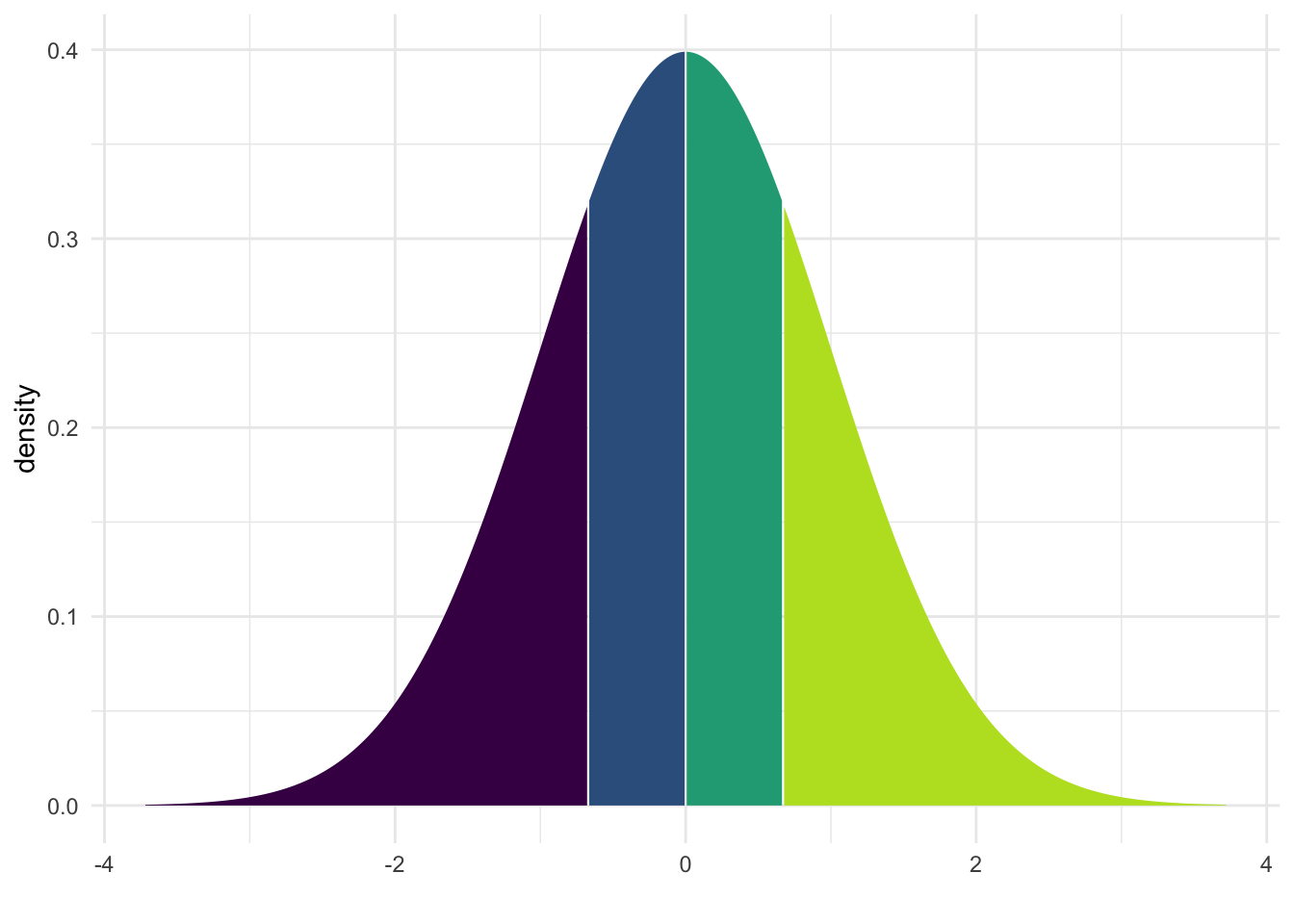
Abbildung 6.12 visualisiert verschiedene Quantile. Man beachte, dass alle Regionen gleichgroße Flächen aufweisen.
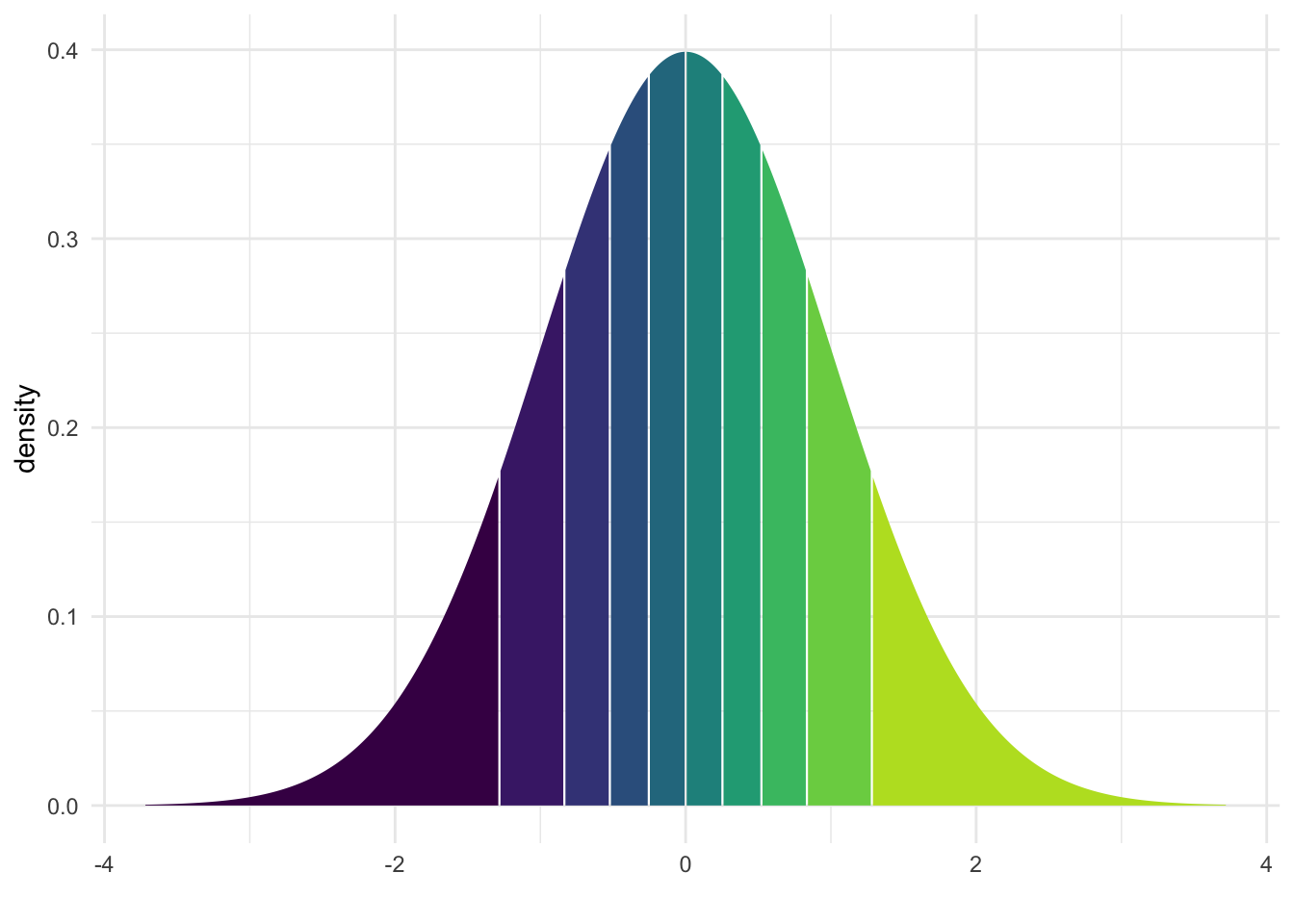
6.4.3 Quantile als sortierte Ordnung
Den R-Befehl quantile() kann man sich einfach nachbauen und damit das Konzept der Quantile besser verstehen. Angenommen, wir wollen wissen, welcher Verkaufspreis mit 90% Wahrscheinlichkeit nicht überschritten wird. Das können wir im Datensatz mariokart wie folgt erreichen:
- Sortiere die Werte aufsteigend.
- Schneide die oberen 10% ab (entfernesie).
- Schaue, was der größte verbleibende Wert ist.
mariokart %>%
arrange(total_pr) %>% # sortiere aufsteigend
slice_head(n = 130) %>% # nur die ersten ca. 90%
summarise(p90 = max(total_pr)) # was ist der größte verbleibende Wert?| p90 |
|---|
| 63 |
Das (annähernd) gleiche Ergebnis liefert quantile():
mariokart %>%
summarise(q90 = quantile(total_pr, .9))| q90 |
|---|
| 62 |
6.4.4 Beispiel: Quantile der IQ-Verteilung
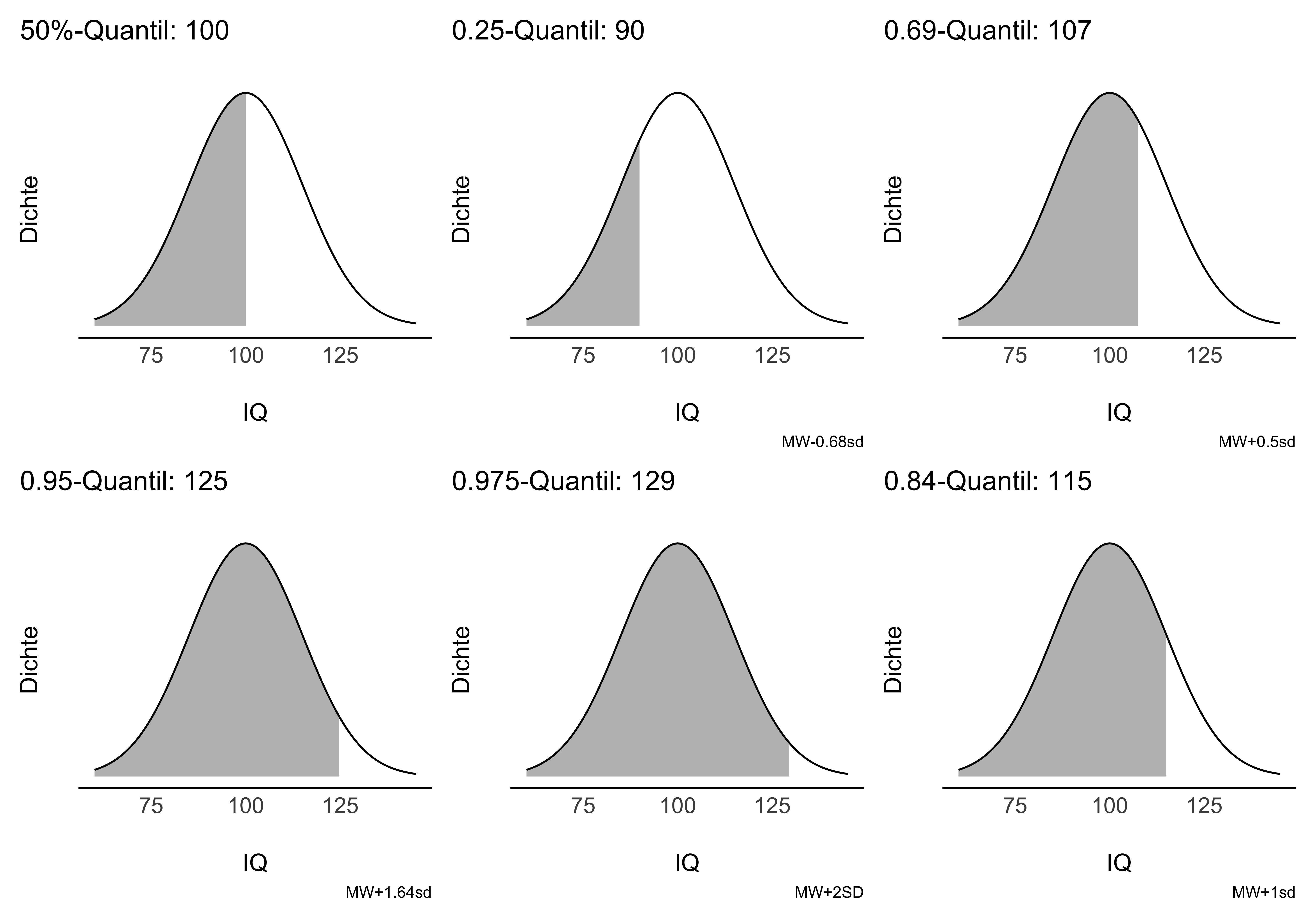
Zur Erinnerung: Die Verteilung des IQ wird gewöhnlich als normalverteilt mit Mittelwert gleich 100 und Streuung gleich 15 angenommen.
Betrachten wir einige häufig verwendete Quantile für die IQ-Verteilung, s. Abbildung 6.13.
6.4.5 Beispiel: Wie groß sind Studierende?
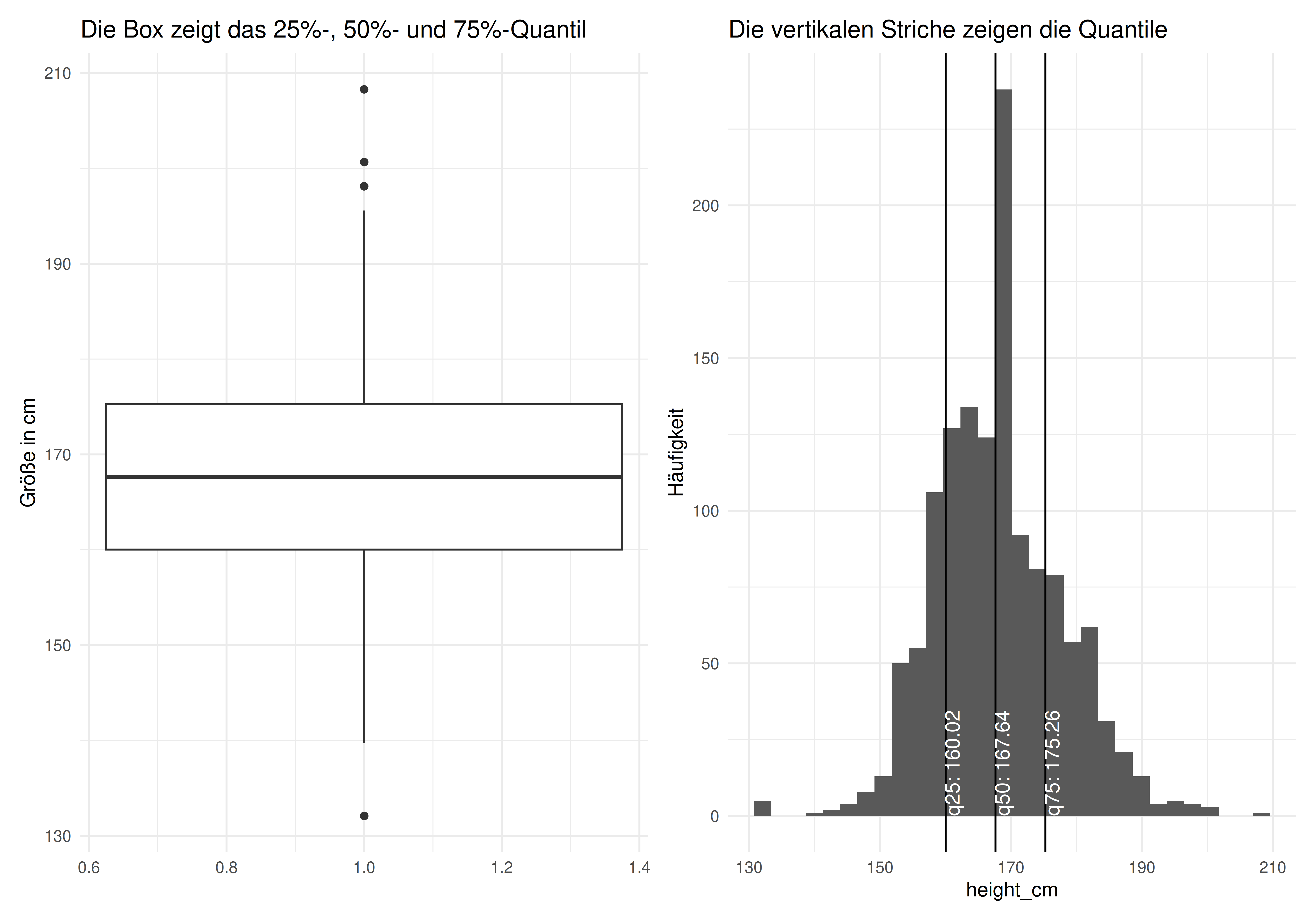
Untersuchen wir die Verteilung der Körpergröße von Studierenden auf Basis eines Datensatzes von Çetinkaya-Rundel et al. (2024).
Das Quantil von z.B. 25% zeigt die Körpergröße der 25% kleinsten Studentis an, analog für 50%, 75%, in Inches bzw. in Zentimetern6.
1data("speed_gender_height", package = "openintro")
height_summary <-
speed_gender_height %>%
2 mutate(height_cm = height*2.54) %>%
select(height_inch = height, height_cm) %>%
3 drop_na() %>%
4 pivot_longer(everything(), names_to = "Einheit", values_to = "Messwert") %>%
5 group_by(Einheit) %>%
6 summarise(q25 = quantile(Messwert, prob = .25),
q50 = quantile(Messwert, prob = .5),
q75 = quantile(Messwert, prob = .75))
height_summary- 1
- Daten importieren
- 2
- Inch in Zentimeter umrechnen
- 3
- Zeilen mit fehlenden Werten löschen
- 4
- In die Langform pivotieren
- 5
- Gruppieren nach Einheit (Inch, Zentimeter)
- 6
- Quantile berechnen (Q1, Q2, Q3)
| Einheit | q25 | q50 | q75 |
|---|---|---|---|
| height_cm | 160 | 168 | 175 |
| height_inch | 63 | 66 | 69 |
Das 25%-Quantil nennt man auch 1. Quartil; das 50%-Quantil (Median) auch 2. Quartil und das 75%-Quantil auch 3. Quartil.
Abbildung 6.14 visualisiert die Quantile und die Häufigkeitsverteilung.
6.5 Lagemaße
🧑🎓 Was ist der Oberbegriff für Median, Mittelwert und so weiter?
🧑🏫 Gute Frage! Wie würden Sie ihn nennen?
Definition 6.8 (Lagemaß) Ein Lagemaß (synonym: Maß der zentralen Tendenz) für eine Verteilung gibt einen Vorschlag, welchen Wert der Verteilung wir als typisch, normal, erwartbar, repräsentativ oder “mittel” ansehen sollten. \(\square\)
Gebräuchliche Lagemaße sind:
- Mittelwert (arithmetisches Mittel)
- Median
- Quantile wie z.\(\,\)B. Quartile
- Minimum (kleinster Wert)
- Maximum (größter Wert)
- Modus (häufigster Wert)
Berechnen wir Lagemaße für den Mariokart-Datensatz, z.\(\,\)B. mit describe_distribution(mariokart), s. Listing 6.2. Es ist übrigens egal, wie Sie die Variablen benennen, die Sie berechnen: mw oder mittelwert oder mean oder mein_krasser_variablenname – alles okay!
describe_distribution(mariokart) |>
# Einige Spalten interessieren uns hier nicht:
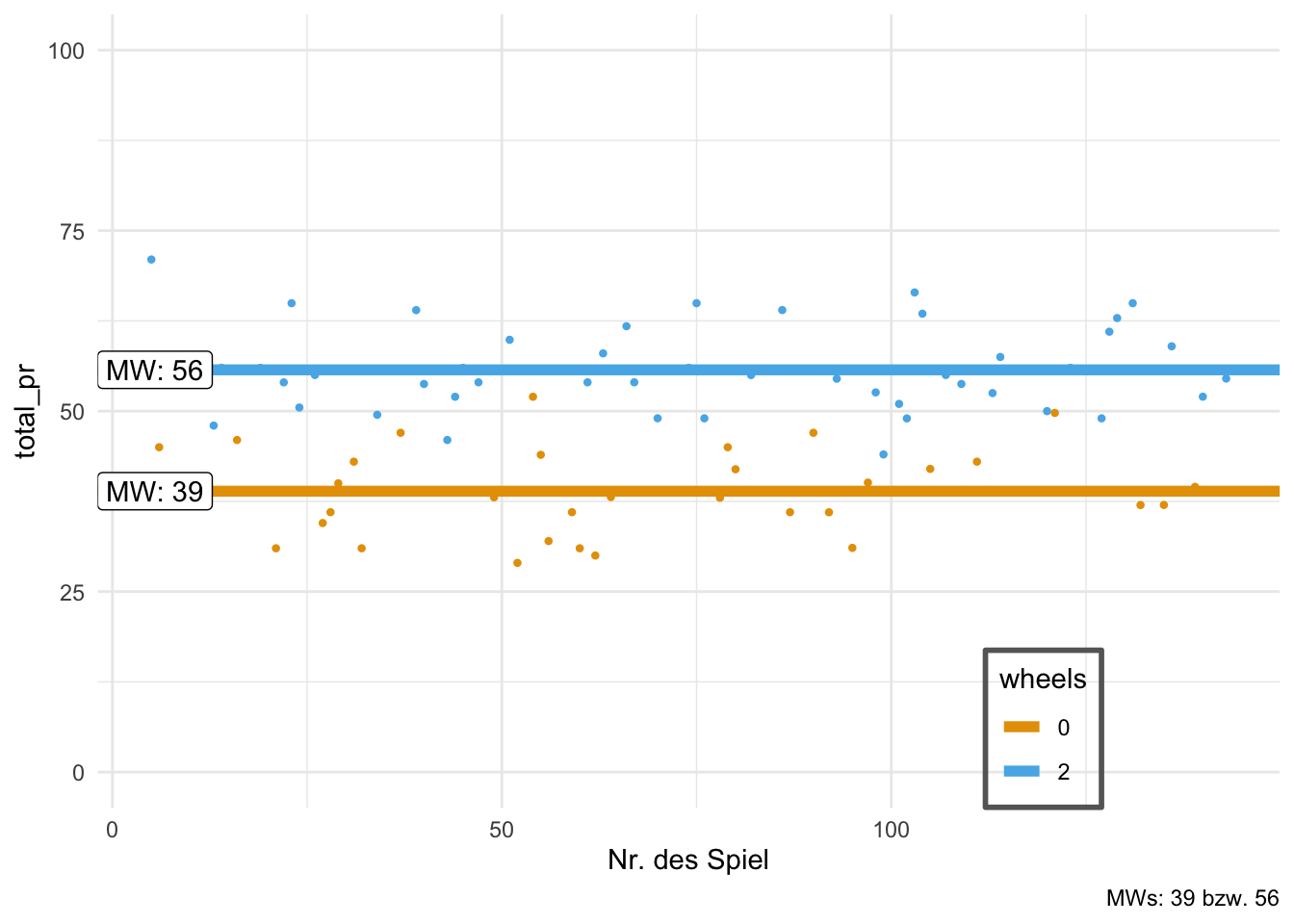
select(-Skewness, -Kurtosis, -n, n_Missing)Häufig möchte man Statistiken wie Lagemaße für mehrere Teilgruppen – z.\(\,\)B. Mittlere Körpergröße von Frauen vs. mittlere Körpergröße von Männern – berechnen und dann vergleichen. Die zugrundeliegende stehende Forschungsfrage könnte lauten: “Unterscheidet sich der Mittelwert der Körpergröße von Frauen und Männern?” Oder vielleicht: “Hängt das Geschlecht mit der Körpergröße zusammen?” Anders ausgedrückt: Körpergröße \(y\) ist eine Funktion des Geschlechts \(G\). Die Modellformel könnte also lauten: \({y} \;{ \sim } \; {G}\). Gruppierte Lagemaße lassen sich in R z.\(\,\)B. so berechnen, s. Listing 6.3.
mariokart_lagemaße_gruppiert <-
mariokart %>%
group_by(wheels) %>% # neue Zeile, der Rest ist gleich!
summarise(mw = mean(total_pr))| wheels | mw |
|---|---|
| 0 | 41 |
| 1 | 44 |
| 2 | 61 |
| 3 | 70 |
| 4 | 65 |
Abbildung 6.16 zeigt ein Beispiel für ungruppierte (links) bzw. gruppierte (rechts) Mittelwerte; vgl. Abbildung 6.5. Wie man in dem Diagramm sieht, kann das Residuum kleiner werden bei einer Gruppierung (im Vergleich zu einem ungruppierten, “globalen” Mittelwert): Innerhalb der Gruppe ohne Lenkräder und innerhalb der Gruppe mit 2 Lenkrädern sind die Abweichungen zu ihrem Gruppen-Mittelwert relativ gering – im Vergleich zu den Abweichungen der Preise zum ungruppierten Mittelwert.
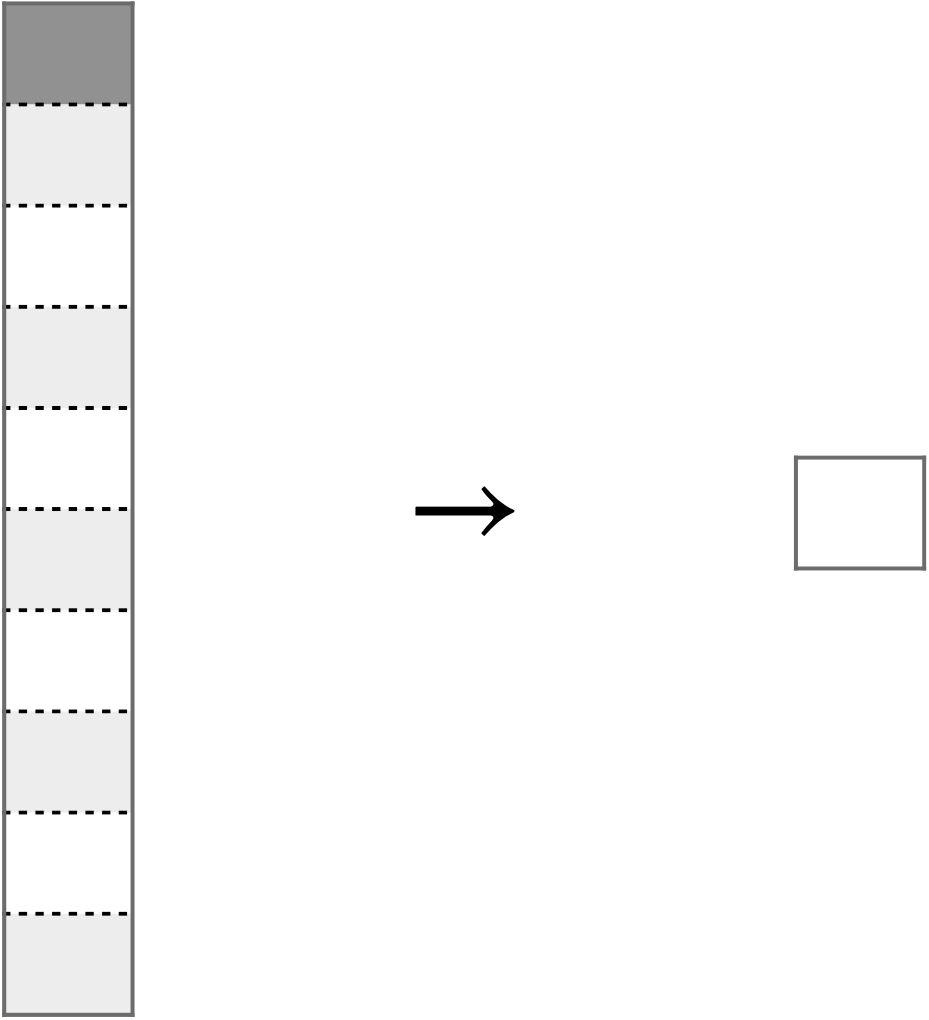
Definition 6.9 (Punktmodell) Ein Modell, welches für alle Beobachtungen ein und denselben Wert annimmt (vorhersagt), heißt Punktmodell. Anders gesagt, fasst ein Punktmodell eine Wertereihe (häufig ist das eine Tabellenspalte) zu einer einzelnen Zahl zusammen, einem “Punkt” in diesem Sinne, s. Abbildung 6.15. \(\square\)
Mittelwert, Median und Quartile sind Beispiele für Punktmodelle: Sie fassen eine Verteilung zu einem einzelnen Wert zusammen und geben uns ein “Bild” der Daten, machen sie uns verständlich – sie sind uns also ein Modell.
6.6 Wie man mit Statistik lügt
Es heißt, mit Statistik könne man vortrefflich lügen. Woran liegt das? Der Grund ist, dass die Statistik Freiheitsgrade lässt: Es gibt nicht nur einen richtigen Weg, um eine statistische Analyse durchzuführen. Viele Wege führen nach Rom (aber nicht alle). Um Manipulationsversuche abzuwehren oder einfache Fehler und Unschärfen ohne böse Absicht aufzudecken, gibt es ein probates Gegenmittel: Transparenz. Analysen sollten transparent sein: Das Vorgehen und die zugrundeliegenden Entscheidungen sollte man offenlegen. Hier ist eine (nicht abschließende!) Checkliste, was Sie nachprüfen sollten, um die Belastbarkeit einer Analyse sicherzustellen Wicherts et al. (2016):
- Wurde die Art und die Zeitdauer der Datenerhebung vorab festgelegt und berichtet?
- Wurden ausreichend Daten gesammelt (z.\(\,\)B. mind. 20 Beobachtungen pro Gruppe)?
- Wurden alle untersuchten Variablen berichtet?
- Wurden alle durchgeführten Interventionen berichtet?
- Wurden Daten aus der Analyse entfernt? Wenn ja, gibt es eine (stichhaltige) Begründung?
Stellen Sie hohe Anforderungen an die Transparenz einer statistischen Analyse. Nur durch Nachprüfbarkeit können Sie sich von der Stichhaltigkeit der Ergebnisse und deren Interpretation überzeugen.
6.7 Vertiefung
Beispiel 6.9 (Survival-Tipp) Eine Studentin aus dem Bachelorstudiengang Angewandte Medien- und Wirtschaftspsychologie mit Schwerpunkt Data Science berichtet ihre “Survival-Tipps” für Statistik.
- Wenn man mal nicht weiterkommt, hilft es auch mal ein paar Tage Abstand von R und Statistik zu nehmen.
- Es hilft, sich während des Semesters neue Begriffe und ihre Erklärung zusammenschreiben.
- Gut ist auch, sich mit KommilitonInnen auszutauschen oder in höheren Semestern nach Tipps zu fragen. \(\square\)
🧑🎓 Irgendwie kann ich mir R-Code so schlecht merken.
🧑🏫 Frag doch mal ChatGPT oder einen anderen Chatbot – dort bekommt man auch R-Code ausgegegeben.
Übungsaufgabe 6.10 (Übungsfragen vom Chat-Bot) Fragen Sie einen Chat-Bot wie ChatGPT nach Übungsaufgaben. Sie können sich an folgenden Prompt orientieren. Empfehlenswert ist mit verschiedenen Prompts zu experimentieren.
🧑🎓 Ich bin Student in einem Bachelor-Studiengang. Gerade bereite ich mich auf die Klausur im Fach “Grundlagen der Statistik” vor. Bitte schreibe mir Aufgaben, die mir helfen, mich auf die Prüfung vorzubereiten. Die Fragen sollten folgende Themen beinhalten: Maße der zentralen Tendenz, Grundlagen von R, Skalenniveau (z.\(\,\)B. Nominalskala vs. Intervallskala), Verteilungsformen, Normalverteilungen, z-Werte. Bitte schreibe die Aufgabe im Stil von Richtig-Falsch-Aufgaben. Schreibe ca. 10 Aufgaben. \(\square\)
6.8 Quiz
Was versteht man unter dem “File-Drawer-Problem” (Schubladenproblem) im Kontext wissenschaftlicher Redlichkeit? Überlegen Sie, wie selektives Berichten die statistische Gesamtlage verzerrt.
Wenn nur “schöne” Ergebnisse veröffentlicht werden und negative Befunde in der Schublade bleiben, entsteht ein verzerrtes Bild (Publikationsbias). Dies gilt als wissenschaftliches Fehlverhalten.
- Richtig
- Falsch
- Falsch
- Falsch
- Falsch
Was ist das entscheidende Merkmal eines “Punktmodells” in der Statistik? Denken Sie an die Anzahl der vorhergesagten Werte.
Ein Punktmodell fasst eine Wertereihe zu einer einzigen Zahl zusammen. Jede Person erhält somit die gleiche Vorhersage, unabhängig von anderen Merkmalen.
- Falsch
- Falsch
- Falsch
- Richtig
- Falsch
Sie haben einen Vektor mit den Werten: 10, 20, 30, 40. Wie berechnen Sie den Median für diese gerade Anzahl an Beobachtungen (\(n=4\))?
Bei einer geraden Anzahl an Werten gibt es kein einzelnes “mittleres” Element. Man berechnet stattdessen den Durchschnitt der beiden Werte, die der Mitte am nächsten liegen.
- Falsch
- Richtig
- Falsch
- Falsch
- Falsch
Warum kann ein gruppiertes Mittelwert-Modell (z. B. getrennt nach Geschlecht) besser sein als ein ungruppierter Mittelwert? Beziehen Sie sich auf die Fehlerbalken (Residuen).
Durch die Berücksichtigung einer Gruppierung (z. B. \(y \sim G\)) passt sich das Modell besser an die Daten an. Dies führt dazu, dass die Vorhersagefehler innerhalb der Gruppen oft deutlich sinken.
- Falsch
- Falsch
- Falsch
- Richtig
- Falsch
Ein Immobilienportal gibt das 0.90-Quantil für Hauspreise in einer Stadt mit 800.000 Euro an. Wie ist dieser Wert für einen potenziellen Käufer zu interpretieren? Nutzen Sie die Definition von Quantilen als Schwellenwerte.
Ein p-Quantil ist der Wert, der von p Prozent der Werte nicht überschritten wird. Hier liegen also 90 % der Preise unter oder auf der Marke von 800.000 Euro.
- Richtig
- Falsch
- Falsch
- Falsch
- Falsch
Was bedeutet die Aussage \(y = m + e\) im Kontext eines statistischen Punktmodells? Betrachten Sie die Komponenten der Gleichung.
In der Statistik gilt: Daten = Modell + Rest. Der beobachtete Wert \(y\) wird durch den Modellwert \(m\) vorhergesagt, wobei \(e\) die Abweichung beschreibt.
- Falsch
- Falsch
- Falsch
- Falsch
- Richtig
In einem Datensatz ist der Mittelwert deutlich größer als der Median. Was lässt sich daraus über die Form der Verteilung ableiten? Stellen Sie sich die Position der Ausreißer im Verhältnis zum “Zentrum” vor.
Wenn der Mittelwert “nach rechts” (zu höheren Werten) gezogen wird, liegt eine rechtsschiefe Verteilung vor. Extreme Werte am oberen Ende der Skala beeinflussen den Mittelwert stärker als den Median.
- Falsch
- Falsch
- Richtig
- Falsch
- Falsch
Sie führen in R den Befehl lm(total_pr ~ 1, data = mariokart) aus. Welchen statistischen Kennwert erhalten Sie als “Intercept” (Achsenabschnitt) zurück? Denken Sie an die Definition eines Nullmodells ohne unabhängige Variablen.
Ein lineares Modell mit der Formel ~ 1 ist ein Punktmodell. Dabei schätzt R den Achsenabschnitt so, dass er dem Mittelwert der abhängigen Variable entspricht.
- Falsch
- Falsch
- Falsch
- Falsch
- Richtig
Ein Statistikkurs besteht aus fünf Personen mit den Noten 1, 2, 3, 4 und 5. Der Professor behauptet, der Mittelwert von 3 sei ein “Modell” für diese Daten. Welche mathematische Eigenschaft des Mittelwerts stützt diese Aussage am besten? Betrachten Sie die Summe der Abweichungen (Residuen) vom Mittelwert. Überlegen Sie, was passiert, wenn Sie alle \(e_i = y_i - \bar{x}\) addieren.
Der Mittelwert wirkt wie ein physikalischer Schwerpunkt (Wippe). Die Summe der Abweichungen nach oben und unten gleicht sich exakt aus, sodass ihre Summe Null ergibt.
- Falsch
- Falsch
- Falsch
- Falsch
- Richtig
Gegeben ist eine normalverteilte Variable (IQ) mit einem Mittelwert von 100 und einer Streuung von 15. Ein Student erzielt einen Wert von 130 Punkten. Welcher Anteil der Bevölkerung liegt laut der 68-95-99.7-Prozentregel über diesem Wert? Kombinieren Sie das Wissen über die Standardabweichung mit der Flächenverteilung.
Ein Wert von 130 entspricht dem Mittelwert plus zwei Standardabweichungen. Innerhalb von zwei Standardabweichungen liegen 95 %, außerhalb also 5 %. Da die Verteilung symmetrisch ist, entfallen 2,5 % auf den Bereich über 130.
- Falsch
- Richtig
- Falsch
- Falsch
- Falsch
6.9 Aufgaben
Ein Teil der folgenden Aufgaben kann Stoff beinhalten, den Sie noch nicht kennen, aber später kennenlernen. Ignorieren Sie daher Aufgaben(teile) mit (noch) unbekanntem Stoff.
Die Webseite Statistik1 - Aufgabensammlung stellt eine Reihe von einschlägigen Übungsaufgaben bereit. Suchen Sie dort im entsprechenden Kapitel.
- kennwert-robust
- mw-berechnen
- mariokart-max2
- nasa01
- mariokart-mean1
- wrangle10
- summarise01
- mariokart-max1
- schiefe1
- mariokart-mean2
- summarise03
- mariokart-mean4
- mariokart-mean3
- summarise02
Schauen Sie sich auch mal auf datenwerk.netlify.app die Aufgaben zu z.\(\,\)B. dem Tag EDA an.
6.10 Literaturhinweise
Es gibt viele Lehrbücher zu den Grundlagen der Statistik; die Inhalte dieses Kapitels gehören zu den Grundlagen der Statistik. Vielleicht ist es am einfachsten, wenn Sie einfach in Ihrer Bibliothek des Vertrauens nach einem typischen Lehrbuch schauen. Beispiel für Lehrbücher sind Mittag & Schüller (2020) oder Oestreich & Romberg (2014); ein Klassiker ist Bortz & Schuster (2010). Einen Fokus auf R legt Sauer (2019). Wer vor Englisch nicht zurückschreckt, ist mit Çetinkaya-Runde & Hardin (2021) oder Poldrack (2023) gut beraten. Beide Bücher sind online verfügbar. Tipp: Mit dem Browser lässt sich englischer Text auf einer Webseite auf auf Deutsch übersetzen.
https://en.wikipedia.org/wiki/Average_human_height_by_country↩︎
316 Tsd Euro↩︎
Nein. Es beschreibt weder das Vermögen der Studierenden noch das des Fußballers gut.↩︎
Er bleibt gleich, verändert sich also nicht: Der Median ist robust, er verändert sich nicht oder kaum, wenn Extremwerte vorliegen.↩︎
ca. 84 Tsd Euro↩︎
1 Inch entspricht 2.54cm↩︎
https://data-se.netlify.app/2022/02/23/data-sets-for-for-teaching/↩︎