glimpse(mariokart)4 Daten umformen
Schlüsselwörter
Statistik, Prognose, Modellierung, R, Datenanalyse, Regression
\[ \definecolor{ycol}{RGB}{230,159,0} \definecolor{modelcol}{RGB}{86,180,233} \definecolor{errorcol}{RGB}{0,158,115} \definecolor{beta0col}{RGB}{213,94,0} \definecolor{beta1col}{RGB}{0,114,178} \definecolor{xcol}{RGB}{204,121,167} \]
4.1 Einstieg
4.1.1 Lernziele
- Sie können folgende Verben des Datenjudo anwenden:
arrange,filter,select,summarise,group_by,mutate. - Sie können R-Befehle mit der “Pfeife” verketten.
Übungsaufgabe 4.1 (Mariokart importieren) Importieren Sie den Datensatz mariokart, s. Kapitel 3.7.3. Probieren Sie alle in diesem Kapitel vorgestellten Verben des Datenjudos aus, zunächst, indem Sie einfach den R-Code kopieren und selber ausführen. Danach überlegen Sie sich Varianten. \(\square\)
4.1.2 R-Code zum Copy-Pasten
Sie finden den R-Code für jedes Kapitel hier. \(\square\)
4.1.3 Frag den Bot
🧑🎓 Erkläre einem Fünfjährigen, warum Statistik nützlich ist.
🤖 Okay, hör zu. Stell dir vor, du hast viele Spielzeugautos und du willst herausfinden, welches Auto am meisten bespielt wird. Du kannst jeden Tag zählen, wie oft du jedes Auto benutzt hast. Aber das wäre sehr mühsam und könnte schnell durcheinander gebracht werden. Stattdessen kannst du mit Statistik eine einfachere Methode finden. Du kannst zum Beispiel eine Liste machen und jedes Auto mit einer bestimmten Farbe markieren. Dann kannst du jeden Tag einfach zählen, wie oft du jede Farbe verwendet hast. Am Ende kannst du herausfinden, welches Auto am meisten bespielt wurde, indem du siehst, welche Farbe am meisten verwendet wurde. Das ist ein Beispiel dafür, wie Statistik uns dabei helfen kann, Muster in großen Datensätzen zu finden und Entscheidungen zu treffen, ohne alles einzeln zu zählen.1
4.1.4 Quiz zum Einstieg
Vielleicht fordert Sie die Lehrkraft zu einem Einstiegsquiz auf, etwa mittels der Plattform antworte.jetzt. Alternativ überlegen Sie sich selber 10 Quiz-Aufgaben zum Stoff des letzten Kapitels.
Definition 4.1 (Datenjudo) Mit Datenjudo meint man den Prozess der Aufbereitens, Umformens oder Zusammenfassen von Daten, sowohl für einzelne Beobachtungen (Zeilen einer Datentabelle) oder Variablen (Spalten einer Datentabelle) oder einer ganzen Datentabelle. \(\square\)
4.1.5 Praxisbezug: Aus dem Alltag des Datenwissenschaftlers
Denkt man an Data Science, stellt man sich coole Leute vor (in San Francisco oder Berlin), die an abgefahrenen Berechnungen mit hoch komplexen statistischen Modellen für gigantische Datenmengen basteln. Laut dem Harvard Business Review, verbringen Data Scientisten allerdings “80\(\,\)%” ihrer Zeit mit dem Aufbereiten von Daten (Bowne-Anderson, 2018). Ja: mit uncoolen Tätigkeiten wie Tippfehler aus Datensätzen entfernen oder die Daten überhaupt nutzbar und verständlich zu machen.
Das zeigt zumindest, dass das Aufbereiten von Daten a) wichtig ist und b) dass man allein damit schon weit kommen kann. Eine gute Nachricht ist (vielleicht), dass das Aufbereiten von Daten keine aufwändige Mathematik verlangt, stattdessen muss man ein paar Handgriffe und Kniffe kennen. Daher passt der Begriff Datenjudo vielleicht ganz gut. Kümmern wir uns also um das Aufbereiten bzw. Umformen von Daten, um das Datenjudo. 🔢🤹 \(\square\)
Beispiel 4.1 (Beispiel für Datenjudo) Beispiele für typische Tätigkeiten des Datenjudos sind:
- Zeilen filtern (z.\(\,\)B. nur Studierenden des Studiengangs X)
- Zeilen sortieren (z.\(\,\)B. Studierenden mit guten Noten in den oberen Zeilen)
- Spalten wählen (z.\(\,\)B. 100 langweilige Spalten ausblenden)
- Spalten in eine Zahl zusammenfassen (z.\(\,\)B. Notenschnitt der 1. Klausur)
- Tabelle gruppieren (z.\(\,\)B. Analyse getrennt nach Standorten)
- Werte aus einer Spalte verändern oder neue Spalte bilden (z.\(\,\)B. Punkte in Prozent-Richtige umrechnen).
- … \(\square\)
4.1.6 Mach’s einfach
Klingt fast zu schön, um wahr zu sein (s. Abbildung 4.1).

Es gibt einen (einfachen) Trick, wie man umfangreiche Datenaufbereitung elegant geregelt kriegt. Der Trick besteht darin, komplexe Operationen in mehrere einfache Teilschritte zu zergliedern. (In gewisser Weise besteht das Wesen einer Analyse eben darin: die Zerlegung eines Gegenstands in seine Bestandteile.) Man könnte vom “Lego-Prinzip” sprechen, s. Abbildung 4.2. Im linken Teil von Abbildung 4.2 sieht man ein (recht) komplexes Gebilde. Zerlegt man es aber in seine Einzelteile, so sind es deutlich einfachere geometrische Objekte wie Dreiecke oder Kreise (rechter Teil des Diagramms). Damit Sie es selber einfach machen können, müssen Sie selber Hand anlegen. Importieren Sie daher den Datensatz mariokart, s. Kapitel 3.7.3.

Werfen wir einen Blick hinein (to glimpse):
Beispiel 4.2 (Der Datenguru in Aktion) Sie arbeiten immer noch bei dem großen Online-Auktionshaus. Mittlerweile haben Sie sich den Ruf des “Datenguru” erworben. Vielleicht, weil Sie behauptet haben, Data Science sei zu 80% Datenjudo, das hat irgendwie Eindruck geschindet … Naja, jedenfalls müssen Sie jetzt mal zeigen, dass Sie nicht nur schlaue Sprüche draufhaben, sondern auch die Daten ordentlich abbürsten können. Sie analysieren dafür im Folgenden den Datensatz mariokart. Na, dann los. \(\square\)
4.2 Die Verben des Datenjudos
Im R-Paket dplyr, das wiederum Teil des R-Pakets tidyverse ist, gibt es eine Reihe von R-Befehlen, die das Datenjudo in eine Handvoll einfacher Verben herunterbrechen. (Falls Sie das R-Paket tidyverse noch nicht installiert haben sollten, wäre jetzt ein guter Zeitpunkt dafür.) Die wichtigsten Verben des Datenjudos schauen wir uns im Folgenden an. Wir betrachten dazu im Folgenden einen einfachen (Spielzeug-)Datensatz, an dem wir zunächst die Verben des Datenjudos vorstellen, s. Tabelle 4.1.
| id | name | gruppe | note |
|---|---|---|---|
| 1 | Anni | A | 2.7 |
| 2 | Berti | A | 2.7 |
| 3 | Charli | B | 1.7 |
Die Verben des Datenjudos wohnen im Paket dplyr, welches gestartet wird, wenn Sie library(tidyverse) eingeben. Falls Sie vergessen, das Paket tidyverse zu starten, dann funktionieren diese Befehle nicht.
4.2.1 Tabelle sortieren: arrange
Sortieren der Zeilen ist eine einfache, aber häufige Tätigkeit des Datenjudos, s. Abbildung 4.3.

arrange: Hier wurden die Noten aufsteigend sortiert.
Beispiel 4.3 (Was sind die höchsten Preise?) Sie wollen mal locker anfangen. Daher stellen Sie sich folgende Frage: Was sind denn eigentlich die höchsten Preise, für die das Spiel Mariokart über den Online-Ladentisch geht? Die Spalte für den Verkaufsprei heißt offenbar total_pr (s. Datensatz mariokart). In Excel kann die Spalte, nach der man die Tabelle sortieren möchte, einfach anklicken. Ob das in R auch so einfach geht?
Die Funktion arrange macht es uns ziemlich einfach, s. Tabelle 4.2.
arrange(mariokart, total_pr)total_pr
| id | duration | n_bids | cond | start_pr | ship_pr | total_pr | ship_sp | seller_rate | stock_photo | wheels |
|---|---|---|---|---|---|---|---|---|---|---|
| 2.6e+11 | 1 | 17 | used | 0.99 | 0 | 29 | standard | 4982 | yes | 0 |
| 1.2e+11 | 1 | 12 | used | 0.01 | 0 | 30 | standard | 7284 | yes | 0 |
| 2.6e+11 | 1 | 7 | used | 0.99 | 0 | 31 | standard | 4982 | yes | 0 |
| 3.2e+11 | 7 | 14 | used | 1.99 | 0 | 31 | media | 166 | yes | 0 |
| 1.8e+11 | 10 | 3 | used | 30.00 | 0 | 31 | priority | 19 | no | 0 |
| 1.1e+11 | 1 | 16 | used | 0.01 | 0 | 31 | standard | 7284 | yes | 0 |
Übersetzen wir die R-Syntax ins Deutsche:
Hey R,
arrangiere (sortiere) `mariokart`
nach der Spalte `total_pr` (aufsteigend).Gar nicht so schwer. \(\square\)
Übrigens wird in arrange per Voreinstellung aufsteigend sortiert. Setzt man ein Minus vor der zu sortierenden Spalte, wird umgekehrt, also absteigend sortiert:
mario_sortiert <- arrange(mariokart, -total_pr)Übungsaufgabe 4.2 Sortieren Sie die Mariokart-Daten absteigend nach der Anzahl der beigelegten Lenkräder. \(\square\)
4.2.2 Zeilen filtern: filter
Zeilen filtern bedeutet, dass man nur bestimmte Zeilen (Beobachtungen) behalten möchte, die restlichen Zeilen brauchen wir nicht, weg mit ihnen. Wir haben also ein Filterkriterium im Kopf, anhand dessen wir die Tabelle filern, s. Abbildung 4.4.
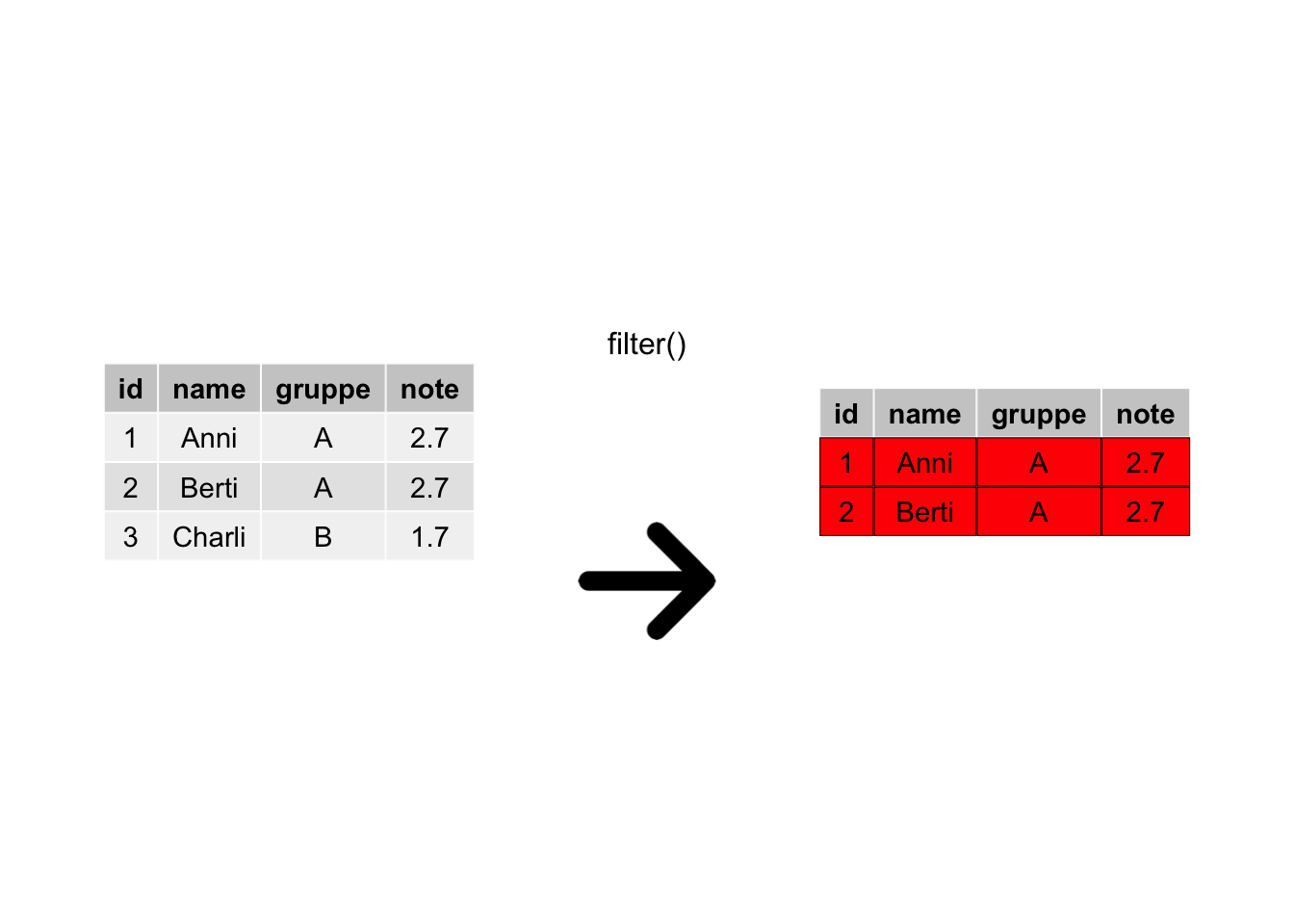
filter: Gruppe B wurde entfernt, also wurde nach Gruppe A gefiltert.
Beispiel 4.4 (Ob ein Foto für den Verkaufspreis nützlich ist?) Als nächstes kommt Ihnen die Idee, mal zu schauen, ob Auktionen mit “Stock-Photo” Ware einen höheren Verkaufspreis erzielen als Auktionen ohne solche Totos.
mariokart_neu <- filter(mariokart, stock_photo == "yes")mariokart_neu | id | duration | n_bids | cond | start_pr | ship_pr | total_pr | ship_sp | seller_rate | stock_photo | wheels |
|---|---|---|---|---|---|---|---|---|---|---|
| 1.5e+11 | 3 | 20 | new | 0.99 | 4 | 52 | standard | 1580 | yes | 1 |
| 2.6e+11 | 7 | 13 | used | 0.99 | 4 | 37 | firstClass | 365 | yes | 1 |
| 2.8e+11 | 3 | 18 | new | 0.99 | 0 | 44 | standard | 7 | yes | 1 |
| 1.7e+11 | 1 | 20 | new | 0.01 | 0 | 71 | media | 820 | yes | 2 |
| 3.6e+11 | 3 | 19 | new | 0.99 | 4 | 45 | standard | 270144 | yes | 0 |
| 1.2e+11 | 1 | 13 | used | 0.01 | 0 | 37 | standard | 7284 | yes | 0 |
Sie filtern also die Tabelle so, dass nur diese Auktionen im Datensatz verbleiben, welche mind. ein Foto haben, mit anderen Worten, Auktionen (Beobachtungen) bei denen gilt: stock_photo == TRUE. \(\square\)
Angestachelt von Ihren Erfolgen möchten Sie jetzt komplexere Hypothesen prüfen: Erzielen Auktionen von neuen Spielen und zwar mit Foto einen höheren Preis als die übrigen Auktionen? Anders gesagt haben Sie zwei Filterkriterien im Blick: Neuheit cond und Foto stock_photo. Nur diejenigen Auktionen, die sowohl Neuheit als auch Foto erfüllen, möchten Sie näher untersuchen (Filtern mit dem logischen UND):
mario_filter1 <-
filter(mariokart, # "&" heißt UND:
stock_photo == "yes" & cond == "new")mario_filter1| id | duration | n_bids | cond | start_pr | ship_pr | total_pr | ship_sp | seller_rate | stock_photo | wheels |
|---|---|---|---|---|---|---|---|---|---|---|
| 1.5e+11 | 3 | 20 | new | 0.99 | 4 | 52 | standard | 1580 | yes | 1 |
| 2.8e+11 | 3 | 18 | new | 0.99 | 0 | 44 | standard | 7 | yes | 1 |
| 1.7e+11 | 1 | 20 | new | 0.01 | 0 | 71 | media | 820 | yes | 2 |
| 3.6e+11 | 3 | 19 | new | 0.99 | 4 | 45 | standard | 270144 | yes | 0 |
| 3.0e+11 | 1 | 15 | new | 1.00 | 3 | 54 | upsGround | 4858 | yes | 2 |
| 2.9e+11 | 1 | 15 | new | 1.00 | 3 | 55 | upsGround | 4858 | yes | 2 |
Hm. Was ist mit den Auktionen, die entweder über (mind.) ein Foto verfügen oder auch neu sind, oder beides (Filtern mit dem logischen ODER)?
mario_filter2 <-
filter(mariokart, # "|" heißt ODER:
stock_photo == "yes" | cond == "new")mario_filter2| id | duration | n_bids | cond | start_pr | ship_pr | total_pr | ship_sp | seller_rate | stock_photo | wheels |
|---|---|---|---|---|---|---|---|---|---|---|
| 1.5e+11 | 3 | 20 | new | 0.99 | 4.0 | 52 | standard | 1580 | yes | 1 |
| 2.6e+11 | 7 | 13 | used | 0.99 | 4.0 | 37 | firstClass | 365 | yes | 1 |
| 3.2e+11 | 3 | 16 | new | 0.99 | 3.5 | 46 | firstClass | 998 | no | 1 |
| 2.8e+11 | 3 | 18 | new | 0.99 | 0.0 | 44 | standard | 7 | yes | 1 |
| 1.7e+11 | 1 | 20 | new | 0.01 | 0.0 | 71 | media | 820 | yes | 2 |
| 3.6e+11 | 3 | 19 | new | 0.99 | 4.0 | 45 | standard | 270144 | yes | 0 |
Zur Erinnerung: Logische Operatoren sind in Kapitel 3.8 erläutert.
Übungsaufgabe 4.3 Hier könnte man noch viele interessante Hypothesen prüfen, denken Sie sich und tun das auch. \(\square\)
Übungsaufgabe 4.4 Filtern Sie die Spiele mit nur einem Lenkrad und ohne Versandkosten. \(\square\)
Übungsaufgabe 4.5 Filtern Sie die Spiele mit nur einem Lenkrad, die einen überdurchschnittlichen Verkaufspreis erzielen. Tipp: Nutzen Sie die Funktion describe_distribution, um den Mittelwert einer Variable des Datensatzes zu erfahren (diese Funktion wohnt im R-Paket easystats). \(\square\)
4.2.3 Spalten auswählen mit select
Eine Tabelle mit vielen Spalten kann schnell unübersichtlich werden. Da lohnt es sich, eine goldene Regel zu beachten: Mache die Dinge so einfach wie möglich, aber nicht einfacher. Wählen wir also nur die Spalten aus, die uns interessieren und entfernen wir die restlichen, s. Abbildung 4.5 als Beispiel.

select
Beispiel 4.5 (Fokus auf nur zwei Spalten) Ob wohl gebrauchte Spiele deutlich geringere Preise erzielen im Vergleich zu neuwertigen Spielen? Sie entschließen sich, mal ein Stündchen auf die relevanten Daten zu starren. Dafür wählen Sie mit select die relevanten Spalten aus. \(\square\)
mario_select1 <- select(mariokart, cond, total_pr)Der Befehl select erwartet als Input eine Tabelle und gibt (als Output) eine Tabelle zurück – genau wie die meisten anderen Befehle des Datenjudos. Auch wenn Sie nur eine Spalte auswählen, bleibt es eine Tabelle, eben eine Tabelle mit nur einer Spalte.
select erlaubt Komfort; Sie können Spalten auf mehrere Arten auswählen:
select(mariokart, 1, 2) # Spalten 1 und 2
select(mariokart, 2:5) # Spalten 2 *bis* 5
select(mariokart, -1) # Alle Spalte *außer* Spalte 1Übungsaufgabe 4.6 Wählen Sie die Spalten total_pr, cond sowie die zweite Spalte der Tabelle mariokart aus!2 \(\square\)
Vertiefte Informationen zum Auswählen von Spalten mit select finden sich auf der Hilfeseite der Funktion.3
4.2.4 Spalten zu einer Zahl zusammenfassen mit summarise
Beispiel 4.6 (Was ist der mittlere Verkaufspreis?) Mit summarise, s. Listing 4.1, können wir den mittleren Verkaufspreis der Mariokart-Spiele berechnen (50). \(\square\)
So eine lange Spalte mit Zahlen – mal ehrlich: Wer blickt da schon durch? Machen wir uns das Leben leichter, indem wir eine lange Spalte mit Zahlen zu einer einzigen Zahl zusammenfassen. Sagen wir, drei Studierende – Anni, Berti, Charli – haben eine Statistikklausur geschrieben. Die Noten waren 2.7, 2.7 und 1.7. Damit lag der Notenschnitt (der Mittelwert) bei 2.4; s. Abbildung 4.6.

summarise: Hier wurden die Noten anhand des Mittelwerts zusammengefasst.
Fassen wir als Nächstes die Spalte total_pr zu einer Zahl zusammen, und zwar zum Mittelwert. Dann wissen wir, für welchen Preis ein Spiel im Durchschnitt verkauft wird, s. Listing 4.1.
mariokart_mittelwert <- summarise(mariokart,
preis_mw = mean(total_pr))
mariokart_mittelwert| preis_mw |
|---|
| 50 |
Aha! Etwa 50 Dollar erzielte so eine Auktion im Durchschnitt. Ein bisschen abstrakter gesprochen fasst summarise eine Spalte zu einer (einzelnen) Zahl zusammen, s. Listing 4.1.
Eine Alternative, um eine Spalte zu einer Zahl zusammenzufassen, bietet der “Dollar-Operator” ($): mean(mariokart$total_pr). Der Dollar-Operator trennt hier die Tabelle von der Spalte: tibble$spalte. Im Gegensatz zu den Verben des Tidyverse (die immer einer Tabelle zurückliefern), liefert der Dollar-Operator einen Vektor (Spalte) zurück. (Diese wird von mean dann zu einer einzelnen Zahl zusammengefasst.)
Auf welche Art zusammengefasst werden soll, z.\(\,\)B. anhand des Mittelwerts oder Maximalwerts, muss noch zusätzlich innerhalb von summarise angegeben werden.
Übungsaufgabe 4.7 Identifizieren Sie den höchsten Kaufpreis eines Mariokart-Spiels!4 \(\square\)
Übungsaufgabe 4.8 Identifizieren Sie den Mittelwert der Versandkostenpauschale!5 \(\square\)
4.2.5 Tabelle gruppieren
Es ist ja gut und schön, zu wissen, was so ein Spiel im Schnitt kostet. Aber viel interessanter wäre es doch, denken Sie sich, zu wissen, ob die neuen Spiele im Schnitt mehr kosten als die alten? Ob R Ihnen so etwas ausrechnen kann?
🧑🎓 Hallo R, kannst du mir die mittleren Verkaufspreise von alten und neuen Spielen ausrechnen?
🤖 Ich tue fast alles für dich. 🧡
Also gut, R, dann gruppiere die Tabelle, s. Abbildung 4.7.
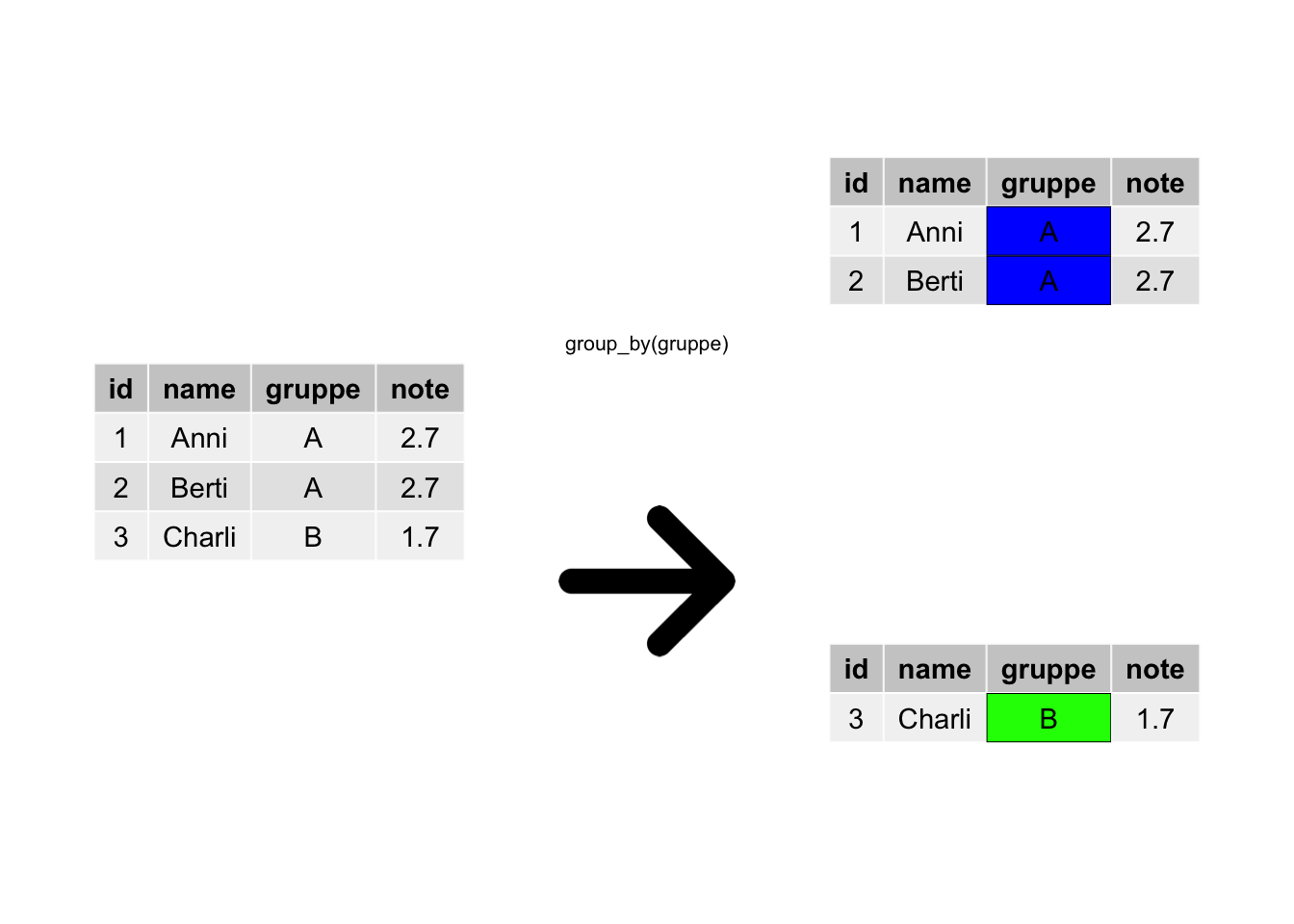
group_by: Hier wurde anhand der Variable gruppe gruppiert.
Durch das Gruppieren wird die Tabelle in “Teiltabellen” – entsprechend der Gruppen – aufgeteilt. Das sieht man der R-Tabelle aber nicht wirklich an. Aber alle nachfolgenden Berechnungen werden für jede Teiltabelle einzeln ausgeführt.
Beispiel 4.7 (Mittlerer Preis pro Gruppe) Gruppieren alleine liefert Ihnen zwei (oder mehrere) Teiltabellen, etwa neue Spiele (Gruppe 1, new) vs. gebrauchte Spiele (Gruppe 2, used). Mit anderen Worten: Wir gruppieren anhand der Variable cond.
mariokart_gruppiert <- group_by(mariokart, cond)Wenn Sie die neue Tabelle betrachte, sehen Sie wenig Aufregendes, nur einen Hinweis, dass die Tabelle gruppiert ist. Jetzt können Sie an jeder Teiltabelle Ihre weiteren Berechnungen vornehmen, etwa die Berechnung des mittleren Verkaufspreises.
summarise(mariokart_gruppiert, preis_mw = mean(total_pr))| cond | preis_mw |
|---|---|
| new | 54 |
| used | 47 |
Ah, die neuen Spiele sind teuerer, wer hätt’s gedacht! Langsam fühlen Sie sich wie ein Datenchecker … 🥷 🦹♀\(\square\)
Übungsaufgabe 4.9
Berechnen Sie den mittleren und maximalen Verkaufspreis getrennt für Spiele mit und ohne Foto!
mariokart_gruppiert_foto <- group_by(mariokart, stock_photo)
mariokart_verkaufspreis_foto <-
summarise(mariokart_gruppiert_foto,
total_pr_avg = mean(total_pr),
total_pr_max = max(total_pr))
mariokart_verkaufspreis_foto| stock_photo | total_pr_avg | total_pr_max |
|---|---|---|
| no | 54 | 327 |
| yes | 48 | 75 |
Bei Auktionen mit Foto wird im Schnitt ein höherer Preis erzielt als ohne Foto. \(\square\)
4.2.6 Spalten verändern mit mutate
Immer mal wieder möchte man Spalten verändern, bzw. deren Werte umrechnen, s. Abbildung 4.8.
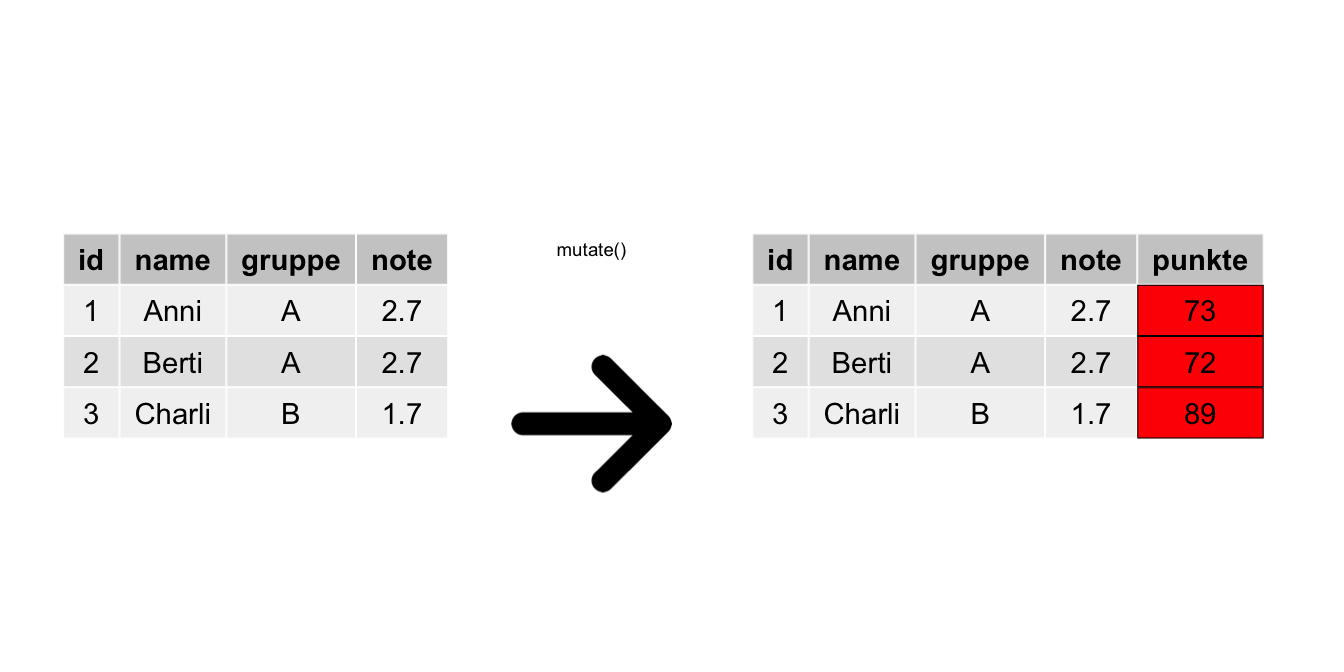
mutate
Beispiel 4.8 Der Hersteller des Computerspiels Mariokart kommt aus Japan; daher erscheint es Ihnen opportun für ein anstehendes Meeting mit dem Hersteller die Verkaufspreise von Dollar in japanische Yen umzurechnen. Nach etwas Googeln finden Sie einen Umrechnungskurs von 1:133.
mariokart_yen <-
mutate(mariokart, total_pr_yen = total_pr * 133)
mariokart_yen <- select(mariokart_yen, total_pr_yen, total_pr)
mariokart_yen |> head() # nur die ersten paar Zeilen| total_pr_yen | total_pr |
|---|---|
| 6856 | 52 |
| 4926 | 37 |
| 6052 | 46 |
| 5852 | 44 |
| 9443 | 71 |
| 5985 | 45 |
Sicherlich werden Sie Ihre Gesprächspartner beeindrucken. \(\square\)
Mit mutate berechnen Sie eine Spalte x (in einer Tabelle) neu. Die Funktion, die Sie in mutate benennen wird für jede Zeile der Spalte x angewendet.
Beispiel 4.9 (Beispiele für Funktionen für mutate) mutate eignet sich, z.\(\,\)B. um Spalten zu addieren, zu multiplizieren oder sonst wie zu transformieren (z.\(\,\)B. den Logarithmus anwenden oder den Mittelwert der Spalte von jeder Zeile abziehen). \(\square\)
Übungsaufgabe 4.10
Rechnen Sie die Dauer der Auktionen von Tagen in Wochen um.
mariokart_duration_wochen <-
mutate(mariokart, duration_week = duration / 7)
mariokart_duration_wochen <-
select(mariokart_duration_wochen, duration, duration_week)
mariokart_duration_wochen |> head() # nur die ersten paar Zeilen| duration | duration_week |
|---|---|
| 3 | 0.43 |
| 7 | 1.00 |
| 3 | 0.43 |
| 3 | 0.43 |
| 1 | 0.14 |
| 3 | 0.43 |
Übungsaufgabe 4.11
Rechnen Sie wieder die Dauer der Auktionen von Tagen in Wochen um, aber runden Sie die Wochen auf ganze Wochen.
mariokart_duration_wochen <-
mutate(mariokart, duration_week = duration / 7)
mariokart_duration_wochen_gerundet <-
mutate(mariokart_duration_wochen, duration_week_gerundet =
round(duration_week, digits = 0))
mariokart_duration_wochen_schmal <-
select(mariokart_duration_wochen_gerundet, duration,
duration_week, duration_week_gerundet)
mariokart_duration_wochen_schmal |> head()| duration | duration_week | duration_week_gerundet |
|---|---|---|
| 3 | 0.43 | 0 |
| 7 | 1.00 | 1 |
| 3 | 0.43 | 0 |
| 3 | 0.43 | 0 |
| 1 | 0.14 | 0 |
| 3 | 0.43 | 0 |
🧟♀️️ Statist – wann braucht man schon sowas!?
🤖 Eigentlich nur dann, wenn man die Fakten gut verstehen will, sonst nicht.
4.2.7 Zeilen zählen mit count
Arbeitet man mit nominalskalierten Daten, ist (fast) alles, was man mit den Daten tun kann, die entsprechenden Zeilen der Tabelle zu zählen: Man könnte z.\(\,\)B. fragen, wie viele neue und wie viele alte Spiele in der Tabelle (Dataframe) mariokart vorhanden sind.
Beispiel 4.10 Nach der letzten Präsentation Ihrer Analyse hat Ihre Chefin gestöhnt: “Oh nein, alles so kompliziert. Statistik! Himmel hilf! Kann man das nicht einfacher machen?” Anstelle von irgendwelchen komplizierten Berechnungen (Mittelwert?) möchten Sie ihr beim nächsten Treffen nur zeigen, wie viele Computerspiele neu und wie viele gebraucht sind (in Ihrem Datensatz). Schlichte Häufigkeiten also. Hoffentlich ist Ihre Chefin nicht wieder überfordert …
mariocart_counted <- count(mariokart, cond)
mariocart_counted| cond | n |
|---|---|
| new | 59 |
| used | 84 |
Aha! Es gibt mehr gebrauchte als neue Spiele. \(\square\)
Jetzt könnte man noch den Anteil (engl. proportion) ergänzen: Welcher Anteil (der 143 Spiele in mariokart) ist neu, welcher gebraucht?
mutate(mariocart_counted, Anteil = n / sum(n))| cond | n | Anteil |
|---|---|---|
| new | 59 | 0.41 |
| used | 84 | 0.59 |
Übungsaufgabe 4.12 Zählen Sie, wie viele der Auktionen ein Stock-Foto enthalten.6 \(\square\)
Übungsaufgabe 4.13 Zählen Sie Sie, wie viele Auktionen ein Foto enthalten – innerhalb der gebrauchten Spiele und innerhalb der neuen Spiele. Anders gesagt: Teilen Sie den Datensatz sowohl nach Zustand als auch nach Foto auf und zählen Sie jeweils, wie viele Spiele/Auktionen in die jeweilige Gruppe gehören.7 \(\square\)
4.2.8 Verben am Fließband
Die Befehle (“Verben”) des Tidyverse sind jeweils für einzelne, typische Aufgaben des Datenaufbereitens (“Datenjudo”) zuständig. Typischerweise erwarten diese Befehle eine Tabelle () als Input und liefern eine Tabelle aus Output zurück, s. Abbildung 4.9. Die Verben des Datenjudos werden beim “Tidydatatutor” anschaulich illustriert.8
flowchart LR A["▥"] --> B[tidyverse-Befehl] --> C["▥"]
4.3 Die Pfeife
🚬 👈Das ist keine Pfeife, wie René Magritte 1929 in seinem berühmten Bild schrieb, s. Abbildung 4.10.
{kind=link}

%>%
|>
4.3.1 Russische Puppen
Computerbefehle, und im Speziellen R-Befehle, kann man “aufeinander” – oder vielmehr: ineinander – stapeln, so ähnlich wie eine russische Puppe (vgl. Kapitel 3.6.3). Schauen wir uns das in einem Beispiel an. Dazu definieren wir zuerst einen Vektor x aus drei Zahlen:
x <- c(1, 2, 3)Und dann kommt unser verschachtelter Befehl:
sum(x - mean(x))
## [1] 0Wie schon erwähnt, arbeitet R so einen “verschachtelten” Befehl von innen nach außen ab:
Start: sum(x - mean(x))
⬇️
Schritt 1: sum(x - 2)
⬇️
Schritt 2: sum(-1, 0, 1)
⬇️
Schritt 3: 0. Fertig. Ganz schön kompliziert!
Soweit kann man noch einigermaßen folgen. Aber das Verschachteln kann man noch extremer machen, dann wird’s wild. Schauen Sie sich mal folgende (Pseudo-)Syntax an:
fasse_zusammen(
gruppiere(
wähle_spalten(
filter_zeilen(meine_daten))))Ein beliebter Fehler ist es übrigens, nicht die richtige Zahl an schließenden Klammern hinzuschreiben, z.\(\,\)B. d(c(b(a(meine_daten)). Falsche Zahl an Klammern!
4.3.2 Die Pfeife zur Rettung
Listing 4.2 ist schon harter Tobak, was für echte Fans. Wäre es nicht einfacher, man könnte Listing 4.2 wie folgt schreiben:
Nimm "meine_daten" *und dann*
filter die gewünschte Zeilen *und dann*
wähle die gewünschte Spalten *und dann*
teile in Subgruppen *und dann*
fasse diese zusammen.Definition 4.2 (Pfeife) “Und dann” heißt auf Errisch %>% oder (synonym) |>. Man nennt diesen Befehl “Pfeife” (engl. pipe). \(\square\)
Hinweis
Der Befehl %>% verknüpft Befehle. Der Shortcut für diesen Befehl ist Strg-Shift-M. Die Pfeife %>% “wohnt” im Paket tidyverse.9
Mittlerweile (Seit R 4.1) ist auch im Standard-R eine Pfeife eingebaut. Die sieht so aus: |>. Die eingebaute Pfeife funktioniert praktisch gleich zur anderen Pfeife, %>%, hat aber den Vorteil, dass Sie nicht tidyverse starten müssen. Da wir tidyverse aber sowieso praktisch immer starten werden, bringt es uns keinen Vorteil, die neuere Pfeife des Standard-R |> zu verwenden. Aber auch keinen Nachteil. Unter Tools > Global Options … können Sie einstellen, welche der beiden Pfeifen-Varianten der Shortcut Strg-Shift-M verwenden soll.
flowchart LR A["▥"] --filter<br>zeilen-->B["▥"] B --wähle<br>spalten--> C["▥"] C --gruppiere--> D["▥"] D --fasse<br>zusammen--> E["▥"]
meine_daten %>%
filter_gewünschte_zeilen() %>%
wähle_gewünschte_spalten() %>%
gruppiere() %>%
fasse_zusammen() Und jetzt kommt’s: So eine Art von Befehls-Verkettung gibt es in R. Schauen Sie sich mal Listing 4.3 an im Vergleich zu Listing 4.2. So eine Pfeifen-Befehlsequenz ist ein wie ein Fließband, an dem es mehrere Arbeitsstationen gibt, s. Abbildung 4.11. Unser Datensatz wird am Fließband von Station zu Station weitergereicht und an jeder Stelle weiterverarbeitet. So könnte Ihre “Pfeifen-Sequenz” für den Mariokart-Datensatz aussehen, s. Listing 4.4.
# Hey R, nimm die Tabelle "mariokart":
mariokart %>%
# filter nur die günstigen Spiele:
filter(total_pr < 100) %>%
# wähle die zwei Spalten:
select(cond, total_pr) %>%
# gruppiere die Tabelle nach Zustand des Spiels:
group_by(cond) %>%
# fasse beide Gruppen nach dem mittleren Preis zusammen:
summarise(total_pr_mean = mean(total_pr)) | cond | total_pr_mean |
|---|---|
| new | 54 |
| used | 43 |
Die Syntax filter(mariokart, total_pr < 100) und die Syntax mariokart |> filter(total_pr < 100) sind identisch. Allgemeiner: d |> f(x) = f(d, x).
4.4 Beispiele für Forschungsfragen
Bevor Sie die Lösungen der folgenden Fallbeispiele lesen, versuchen Sie die Aufgaben selbst zu lösen. Ja, ich weiß, es ist hart, nicht gleich auf die Lösungen zu schauen!
Übungsaufgabe 4.14 (Das teuerste Spiel?) Sie arbeiten als strategischer Assistent der Geschäftsführerin und sind für Faktenchecks und andere Daten-Aufgaben zuständig. Heute sollen Sie zeigen, was Sie können (Schluck).
👩 Ich würde von Ihnen gerne wissen, was das teuerste Spiel ist, aber jeweils für neue und gebrauchte Spiele. Aber nur für Spiele, die mit Foto verkauft wurden!
Lösung
mariokart %>%
filter(stock_photo == "yes") %>%
group_by(cond) %>%
summarise(total_pr_max = max(total_pr))| cond | total_pr_max |
|---|---|
| new | 75 |
| used | 62 |
Die Funktion max liefert den größten Wert eines Vektors zurück:
x <- c(1, 2, 10)
max(x)
## [1] 10Das teuerste Spiel mit Foto kostet 75 Dollar, wenn es neu ist und 62, wenn es gebraucht ist. \(\square\)
Übungsaufgabe 4.15 (Die mittlere Versandpauschale?)
👩 Ich würde gerne die mittlere Versandpauschale wissen, aber getrennt nach Anzahl der Lenkräder, die dem Spiel beigelegt sind. Und ich will nur Gruppen berücksichtigen, die aus mindestens 10 Spielen bestehen!
Lösung
Wenn wir die Anzahl der Spiele zählen in Abhängigkeit der beigelegten Lenkräder (wheels), bekommen wir eine Tabelle mit zwei Spalten: wheels und n. n zählt, wie viele Spiele (Zeilen) in der jeweiligen Gruppe (“Teiltabelle”) von wheels sind.
mariokart %>%
count(wheels)| wheels | n |
|---|---|
| 0 | 37 |
| 1 | 52 |
| 2 | 51 |
| 3 | 2 |
| 4 | 1 |
Aus dieser Tabelle sehen wir, dass 3 oder 4 Lenkräder nur selten (2 bzw. 1 Mal) beigelegt wurden und wir solche Spiele herausfiltern sollten, bevor wir den Mittelwert der Versandkosten ausrechnen:
mariokart %>%
filter(wheels < 3) %>%
group_by(wheels) %>%
summarise(mittlere_versandkosten = mean(ship_pr),
anzahl_spiele = n())| wheels | mittlere_versandkosten | anzahl_spiele |
|---|---|---|
| 0 | 2.7 | 37 |
| 1 | 3.6 | 52 |
| 2 | 2.9 | 51 |
Die Funktion n gibt die Anzahl der Zeilen pro Teiltabelle zurück.
Die mittleren Versandkosten bewegen sich also zwischen 2.7 Dollar und 3.6 Dollar, je nach Anzahl der beigelegten Lenkräder. \(\square\)
Übungsaufgabe 4.16 (Verkaufspreis in Yen?)
👩 Ich würde gerne den Verkaufspreis in Yen wissen, nicht in Euro. Dann rechne mal den mittleren Verkaufspreis aus und ziehe 10 % ab, die wir als Provision unseren Verkäufern zahlen müssen.
Lösung
mariokart %>%
select(total_pr) %>%
mutate(total_pr_yen = total_pr * 133) %>%
summarise(
preis_yen_mw = mean(total_pr_yen),
preis_yen_mw_minus_10proz = preis_yen_mw - 0.1*preis_yen_mw)| preis_yen_mw | preis_yen_mw_minus_10proz |
|---|---|
| 6634 | 5971 |
Wie man sieht kann man in summarise auch mehr als eine Berechnung einstellen. In diesem Fall haben wir zwei Berechnungen angestellt: Einmal den Mittelwert und einmal den Mittelwert minus 10% (des Mittelwerts).
Übungsaufgabe 4.17 (Do It Yourself) Denken Sie sich selber ähnliche Forschungsfragen aus. Stellen Sie diese einer vertrauenswürdigen Kommilitonen bzw. einem vertrauenswürdigen Kommilitonen. DIY! Schauen Sie, ob Ihre Aufgabe richtig gelöst wird. Prüfen Sie streng … \(\square\)
4.5 Praxisbezug
Die Covid19-Epidemie hatte weltweit massive Auswirkungen; auch psychologischer Art wie Vereinsamung, Angst oder Depression. Mulukom et al. (2020) berichten eine Studie, die die psychologischen Auswirkungen untersucht; die Studie ist unter der Projekt-ID tsjnb bei der Open Science Foundation (OSF), <https://osf.io/tsjnb/>, angemeldet. Die Daten wurden mit R ausgewertet. Beispielhaft ist unter https://osf.io/4b9p2 die R-Syntax zu sehen, die die Autoren zur Datenaufbereitung verwendet haben. Einen guten Teil dieser Syntax kennen Sie aus diesem Kapitel. Diese Studie ist, neben einigen vergleichbaren, ein schönes Beispiel, wie Forschung und Praxis ineinander greifen können: Angewandte Forschung als Beitrag zur Lösung eines akuten Problems, der Corona-Pandemie.
4.6 Wie man mit Statistik lügt
Ein (leider) immer mal wieder zu beobachtender “Trick”, um Daten zu frisieren ist, nur die Daten zu berichten, die einem in den Kram passen.
Beispiel 4.11 Eine Analystin 👩 möchte zeigen, dass der Verkaufspreis von Mariokart-Spielen “viel zu niedrig” ist. Es muss ein höherer Wert rauskommen, findet die Analystin. Der mittlere Verkaufspreis (im Datensatz mariokart) liegt bei 50 Euro.
👩 Kann man den Wert nicht … “kreativ verbessern”? Ein paar Statistik-Tricks anwenden?
Um dieses Ziel zu erreichen, teilt die Analystin den Datensatz in Gruppen nach Anzahl der dem Spiel beigelegten Lenkräder (wheels). Dann wird der Mittelwert pro Gruppe berechnet.
mariokart_wheels <-
mariokart %>%
group_by(wheels) %>%
summarise(pr_mean = mean(total_pr),
count_n = n()) # `n` gibt die Anzahl der Zeilen pro Gruppe an
mariokart_wheels| wheels | pr_mean | count_n |
|---|---|---|
| 0 | 41 | 37 |
| 1 | 44 | 52 |
| 2 | 61 | 51 |
| 3 | 70 | 2 |
| 4 | 65 | 1 |
Schließlich berechnet unsere Analystin den ungewichteten Mittelwert über diese 5 Gruppen:
mariokart_wheels %>%
summarise(mean(pr_mean))| mean(pr_mean) |
|---|
| 56 |
Und das Ergebnis lautet: 56 Euro! Das ist doch schon etwas “besser” als 50 Euro.
Natürlich ist es falsch und irreführend, hier einen ungewichteten Mittelwert zu berechnen. Der gewichtete Mittelwert würde wiederum zum korrekten Ergebnis, 50 Euro, führen. \(\square\)
4.7 Fallstudien
4.7.1 Die Pinguine

Übungsaufgabe 4.18 Machen Sie sich zunächst mit dem Pinguin-Datensatz vertraut. Sie finden den Datensatz penguins im R-Paket palmerpenguins, das Sie auf gewohnte Art installieren können (vgl. Kapitel 3.4); im Internet findet man den Datensatz auch als CSV-Datei. Fokussieren Sie Ihre Analyse auf die Zielvariable Gewicht. \(\square\)
Die folgende Datenapp ermöglicht Ihnen, die Verteilung des Körpergewichts zu betrachten, wobei sie die Pinguin-Spezies filtern können sowie eine Mindestlänge des Schnabels verlangen können.
Bearbeiten Sie die Fallstudie zu Pinguinen von Allison Horst. Sie können die Teile auslassen, die Themen beinhalten, die nicht in diesem Kapitel vorgestellt wurden.
Forschungsfragen:
- Was ist das mediane Gewicht von Pinguinen, gruppiert nach Spezies und nach Gewicht?
- Wie viele Pinguine gibt es pro Spezies?
- Wie viel wiegt der schwerste und der leichteste Pinguin pro Spezies?
4.7.2 Fallstudie COVIDiSTRESS

Lesen Sie die Beschreibung der Studie COVIDiSTRESS (Lieberoth et al., 2022). Hier ist ein Abstract:
The COVIDiSTRESS global survey is an international collaborative undertaking for data gathering on human experiences, behavior and attitudes during the COVID-19 pandemic. In particular, the survey focuses on psychological stress, compliance with behavioral guidelines to slow the spread of Coronavirus, and trust in governmental institutions and their preventive measures, but multiple further items and scales are included for descriptive statistics, further analysis and comparative mapping between participating countries. Round one data collection was concluded May 30. 2020. To gather comparable data swiftly from across the globe, when the Coronavirus started making a critical impact on societies and individuals, the collaboration and survey was constructed as an urgent collaborative process. Individual contributors and groups in the COVIDiSTRESS network (see below) conducted translations to each language and shared online links by their own best means in each country.
Die Daten stehen unter https://osf.io/z39us zur freien Verfügung. Sie können diese echten Daten eigenständig analysieren.
Diese Datei beinhaltet die finalen, aufbereiteten Daten. Achtung: Die Datei ist recht groß, ca. 90 MB.
4.8 Quiz
Warum verbringen Datenwissenschaftler laut Harvard Business Review oft 80% ihrer Zeit mit Datenjudo?
Daten in der echten Welt sind selten “sauber”. Das Aufbereiten, Bereinigen und Umformen ist der zeitintensivste Teil der Datenanalyse.
- Richtig
- Falsch
- Falsch
- Falsch
- Falsch
Sie haben einen Datensatz d und möchten nur die Zeilen sehen, bei denen die Variable x größer als 10 ist. Welcher dieser Befehle führt zum Ziel?
Das Filtern von Zeilen basierend auf Bedingungen erfolgt immer mit filter(). select() würde versuchen, Spaltennamen zu finden, die “x > 10” heißen, was scheitert.
- Falsch
- Falsch
- Falsch
- Richtig
- Falsch
Das “Lego-Prinzip” im Datenjudo besagt, dass man komplexe Analysen in kleine Teilschritte zerlegen sollte. Welche der folgenden Aussagen beschreibt einen Nachteil, wenn man dieses Prinzip NICHT beachtet und stattdessen riesige, verschachtelte Funktionen schreibt?
Die Zerlegung in Teilschritte (Lego-Prinzip) dient primär der Übersichtlichkeit und der Fehlervermeidung. Verschachtelter Code ist für Menschen sehr schwer zu interpretieren.
- Falsch
- Richtig
- Falsch
- Falsch
- Falsch
Sie arbeiten mit einem Datensatz über Kunden. Die Variable geschlecht ist nominalskaliert. Was ist die sinnvollste Operation, wenn Sie wissen wollen, wie viele Männer und Frauen im Datensatz sind?
Bei nominalen Daten ist das Zählen der Häufigkeiten die Standardoperation. count() ist dafür die effizienteste Funktion.
- Falsch
- Falsch
- Falsch
- Richtig
- Falsch
Was passiert, wenn Sie arrange(meine_daten, -preis) ausführen? Achten Sie besonders auf das Minuszeichen vor dem Spaltennamen.
In der Funktion arrange() bewirkt ein Minuszeichen vor dem Variablennamen eine absteigende Sortierung (große Werte zuerst).
- Richtig
- Falsch
- Falsch
- Falsch
- Falsch
Angenommen, Sie haben eine Spalte preis_usd. Sie möchten eine neue Spalte preis_euro hinzufügen, ohne die alte Spalte zu löschen. Welches Verb ist hierfür geeignet?
mutate() wird verwendet, um neue Spalten zu berechnen oder bestehende zu verändern. Die Anzahl der Zeilen bleibt dabei immer gleich.
- Falsch
- Falsch
- Falsch
- Falsch
- Richtig
Sie möchten den durchschnittlichen Gewinn pro Verkäufergruppe berechnen. Zuerst nutzen Sie group_by(verkaeufer_typ). Welcher Befehl muss folgen, damit Sie am Ende eine Tabelle erhalten, die pro Gruppe nur noch eine einzige Zeile mit dem Mittelwert enthält?
summarise() reduziert eine Gruppe von Werten auf eine einzelne Kennzahl (z. B. den Mittelwert). mutate() hingegen würde die ursprüngliche Zeilenanzahl beibehalten.
- Falsch
- Falsch
- Richtig
- Falsch
- Falsch
Sie nutzen die Pfeife |> um mehrere Befehle zu verketten. Was ist der entscheidende Vorteil dieser Schreibweise gegenüber verschachtelten Funktionen wie f(g(h(x)))? Betrachten Sie den Lesefluss und die Fehleranfälligkeit bei vielen Klammern.
Die Pfeife (|> oder %>%) verbessert die Lesbarkeit, indem sie Daten wie am Fließband von links nach rechts durch Funktionen reicht. Das erste Argument der nachfolgenden Funktion wird dabei automatisch befüllt.
- Falsch
- Falsch
- Falsch
- Falsch
- Richtig
Stellen Sie sich vor, Sie haben eine Tabelle mit 100 Variablen (Spalten). Sie benötigen für Ihre Analyse jedoch nur die Spalten ID, Preis und Zustand. Welches “Verb” des Datenjudos ist am effizientesten, um die Komplexität des Datensatzes für die folgenden Schritte zu reduzieren? Es geht hierbei um das bewusste Wegwerfen von unnötiger Information.
select() wird verwendet, um eine Teilmenge der Variablen (Spalten) auszuwählen. filter() bezieht sich hingegen auf die Zeilen.
- Falsch
- Falsch
- Falsch
- Falsch
- Richtig
Sie möchten in einem Datensatz nur die Spiele finden, die weniger als 50 Euro kosten und gleichzeitig neuwertig sind. Welche logische Verknüpfung innerhalb der Funktion filter() ist hierfür zwingend erforderlich? Ein falscher Operator würde entweder zu viele oder gar keine Ergebnisse liefern. Denken Sie an die Mengenlehre beim Filtern von Beobachtungen.
Um Zeilen zu finden, die mehrere Kriterien gleichzeitig erfüllen müssen, nutzt man das logische UND (&). Das ODER (|) würde auch gebrauchte Spiele oder teure neue Spiele anzeigen.
- Falsch
- Richtig
- Falsch
- Falsch
- Falsch
4.9 Aufgaben
TippChatGPT
Nutzen Sie einen Chat-Bot wie ChatGPT, um sich Hilfe für die R-Syntax geben zu lassen.
Die Webseite Statistik1 - Aufgabensammlung stellt eine Reihe von einschlägigen Übungsaufgaben bereit. Suchen Sie dort im entsprechenden Kapitel.
4.10 Vertiefung
4.10.1 Fortgeschrittenes R
Hinweis
In weiterführendem Material werden Sie immer wieder auf Inhalte treffen, die Sie noch nicht kennen, die etwa noch nicht im Unterricht behandelt wurden. Seien Sie unbesorgt: In der Regel können Sie diese Inhalte einfach auslassen, ohne den Anschluss zu verlieren. Einfach ignorieren.
Häufig ist es nützlich, die Werte einer Variablen umzukodieren, z.\(\,\)B. “weiblich” in “w” oder in 0. Eine gute Möglichkeit, dies in R umzusetzen, bietet der Befehl case_when; der Befehl wohnt im Tidyverse.10 Im Datenwerk finden Sie dazu Übungen, etwa mutate03.
4.10.2 Hilfe?! Erbie!
R will nicht, so wie Sie wollen? Sie haben das Gefühl, R verweigert störrisch den Dienst, vermutlich rein aus Boshaftigkeit, rein um Sie zu ärgern? Ausführliches Googeln und ChatGPT befragen hat keine Lösung gebracht? Kurz, Sie brauchen die Hilfe eines kundigen Menschens? Sie sollten Ihren Hilfeschrei so artikulieren, dass er nicht nur gehört, sondern auch verstanden wird und einen anderen Menschen veranlasst und ermöglicht, Ihnen zu helfen.
Also: Sie müssen Ihr Problem nachvollziehbar, aber prägnant formulieren. Das nennt man auch ein ERBie: ein einfaches, reproduzierbares Beispiel Ihres Problems mit (R-)Syntax:
- einfach: die einfachste Syntax, die Ihr Problem bzw. die Fehlermeldung produziert. Es bietet sich an, einen einfachen, allgemein bekannten Datensatz zu verwenden, etwa
mtcars - reproduzierbar: Code (z.\(\,\)B. als Textdatei oder in einem Post), der die Fehlermeldung entstehen lässt
Beispiel 4.12 (Beispiel für ein Erbie) Problem: Ich verstehe nicht, warum folgende Fehlermeldung kommt.
Ziel: Ich möchte die Automatikautos filtern (am = 0).
Was ich schon versucht habe: Ich habe folgende Posts gelesen …, aber ohne Erfolg.
Erbie:
data(mtcars)
library(dplyr) # nicht "tidyverse", denn "dplyr" reicht
mtcars %>%
filter(am = 0) # den kürzesten Code, der Ihren Fehler entstehen lässt!
sessionInfo() # gibt Infos zur R-Version etc. ausError in `filter()`Mit dem Paket reprex kann man sich R-Syntax schön formuliert ausgeben lassen. Das ist perfekt, um den Code dann in einem Forum (oder Mail) einzustellen. Dafür müssen Sie nur den Code auswählen, Strg-c drücken und dann reprex::reprex ausführen. Mit Strg-v können Sie die schön formatierte Syntax (sowie die Ausgabe, auch schön formatiert) dann irgendwohin pasten.

Tipp
Posten Sie Ihr Erbie bei https://gist.github.com/ als “public gist”. Hier ist ein Beispiel.

4.10.3 Zertifikate und Online-Kurse
Sie können zu den Inhalten dieses Kapitels Zertifikate erwerben (teilweise kostenlos), indem Sie einen Online-Kurs absolvieren, bei z.\(\,\)B. folgenden Anbietern – Das ist keine Werbung für spezifische Anbieter und kein umfassender Überblick und keine Kaufempfehlung.
4.11 Exkurs
Dall-E 2 ist eine KI, die “realistische Bilder und Kunst aus einer Beschreibung in natürlicher Sprache” erstellt.
👨🏫 I’d like a mixture between robot und professor, in oil painting
🤖 … s. Abbildung 4.13

Der Nutzen künstlicher Intelligenz für die Datenanalyse ist natürlich breiter: Wenn Sie sich z.\(\,\)B. über die Syntax eines bestimmten Befehls (oder allgemeiner: Vorhabens) nicht sicher sind, fragen Sie sich doch mal einen Bot wie ChatGPT.
4.12 Literaturhinweise
Sauer (2019), Kap. 7, gibt eine Einführung in die Datenaufbereitung (mit Hilfe von R), ähnlich zu den Inhalten dieses Kapitels. Mehr in die Tiefe des “Datenjudo” führen; der Autor Hadley Wickham ist in der R-Community sehr bekannt. Er ist einer der Hauptautoren von beliebten R-Paketen wie dplyr und ggplot2. Wickham & Grolemund (2018) Kap. 5 behandeln (etwas ausführlicher) die Themen dieses Kapitels.
Wer sich tiefer in das Datenjudo mit dem Tidyverse einarbeiten möchte, dem sei z.\(\,\)B. dieser Kurs empfohlen.
{kind=link}
Quelle: ChatGTP 3.5, 2023-02-09↩︎
select(mariokart, total_pr, cond, 2)↩︎https://tidyr.tidyverse.org/reference/tidyr_tidy_select.html↩︎
summarise(mariokart, hoechster_preis = max(total_pr))↩︎summarise(mariokart, mw_versand = mean(total_pr))↩︎count(mariokart, stock_photo)↩︎count(mariokart, stock_photo, cond)↩︎Genauer gesagt im Paket
magrittr, welches aber vontidyversegeladen wird. Also nichts, um das Sie sich kümmern müssten.↩︎